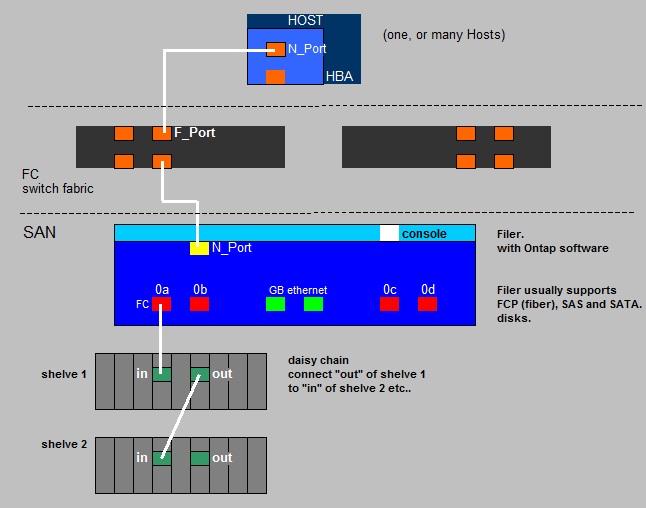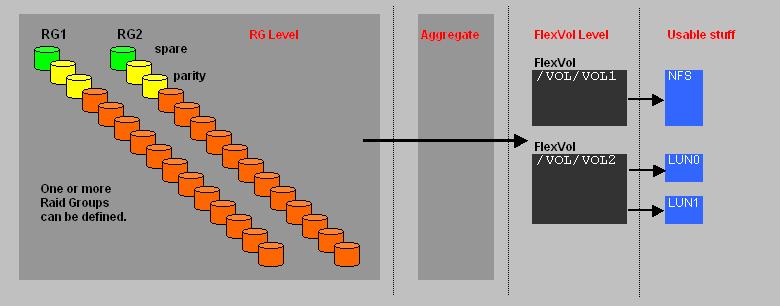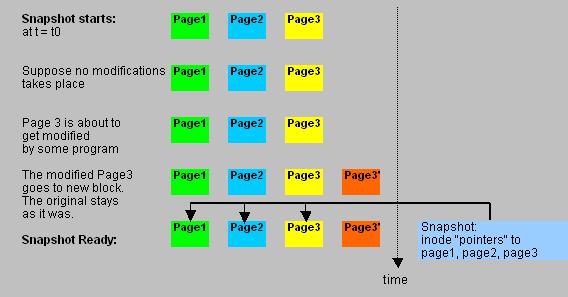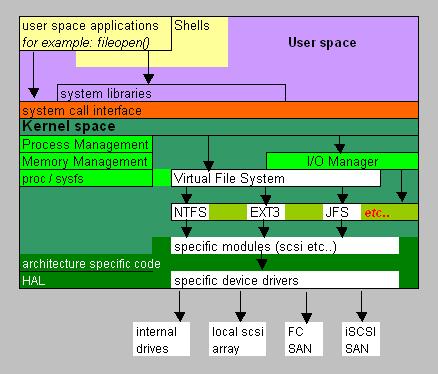

| -From starting byte 0 to byte 445 (incl) -length:446 bytes: Purpose: Initial bootcode (also for loading/reading the partition table) and some error messages |
| -From starting byte 446 to byte 509 (incl) -length: 64 bytes: Purpose: Partition Table 4 Partition Entries each 16 bytes in length |
| bytes 510 and 511 (2 bytes): Purpose: 2 byte closing "Boot record signature" with values: 55 AA |
| Lengt (bytes): | Content: |
| 1 | Boot Indicator (80h=active): |
| 3 | Starting CSH |
| 1 | Partition Type Descriptor |
| 3 | Ending CSH |
| 4 | Starting Sector |
| 4 | Partition size (Sectors) |
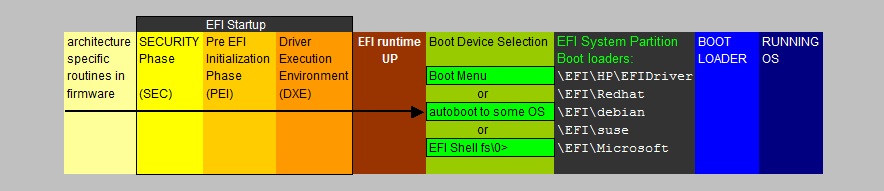
| LBA 0 | Protective MBR |
| LBA 1 | Primary GPT Header |
| LBA 2 | Partition Table starts. Partition Entries 1,2,3,4 |
| LBA 3 - 33 | Partition Entries 5-128 |
| LBA 34 -LBA M | Possible first true Partition (like C:) |
| LBA M+1 - LBA N | Possible Second true Partition (like D:) |
| Other LBA's, except the last 33 LBA's | Possible other partitions up to the last LBA: END_OF_DISK -34 |
| END_OF_DISK - 33 | Partition Entries 1,2,3,4 (copy) |
| END_OF_DISK - 32 | Partition Entries 5-128 (copy) |
| END_OF_DISK - 1 | Secondary GPT Header (copy) |
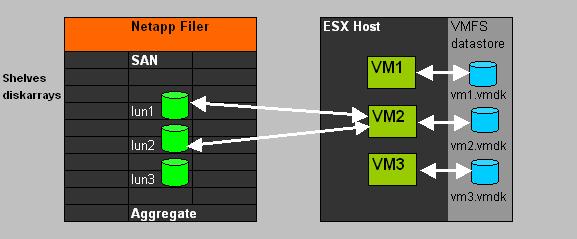
| vm1.nvram | The "firmware" or "BIOS" as presented to the VM by the Host. |
| vm1.vmx | Editable configuration file with specific setting for this VM like amount of RAM, nic info, disk info etc.. |
| vm1-flat.vmdk | The full content of the VM's "harddisk". |
| vm1.vswp | Swapfile associated with this VM. |
| -rdm.vmdk | If the VM uses SAN LUNs, this is a proxy .vmdk for a RAW Lun. |
| .log files | Various log files exists for VM activity records, usable for troubleshooting. The current one is called vmware.log, and a number of former log files are retained. |