Just a few simple tips for Inspecting and Hardening Windows systems.
Version : 2.5
Date : 15/04/2013
By : Albert van der Sel
Level : Basic.
Remark : Hopefully, it's any good.
I have planned to put about 10 (or so) simple sections here.
Some sections describe "something" that might be considered to be "practical", while other sections only discuss some basic theory.
Most sections will end with a "core" or "essential" advice (in red), which expresses the fundamental idea
of that section in one or two sentences.
Be aware though, that this note really is no more than a "super simple" intro on hardening and associated theory.
If you have a substantial experience in IT, this note is probably way too simple. The same holds ofcourse for people in forensics,
However, everybody is certainly invited to read it.
I assume that you want to manage cristal clear, neat, and stable Windows Server and client systems.
I think you can get pretty close to that goal. However, the most decisive factor here is actually
your attitude: If you firmly stick to a set of rules, much like a sort of "religion" so to speak, ;-)
your business systems are certainly more likely to stay healthy.
Sure there exists many "formal" ruling and specifications (like PCI and that sort of stuff), but a lot of material
seems to focus possibly a bit too much on patching, logging and auditing (which all is important ofcourse).
Since not all aspects around security mechanisms in Windows, is "fully open", I'am also afraid that my text
below might appear "clumsy" at certain times, but I hope it all stays "minor" (I'am not fully sure of that fact).
There is even a Legal issue:
Sorry to say this, but I almost forgot. Maybe you might think the following is nonsense, but it's really not.
Although this note contains only very trivial info, the following must be very clear:
When you inspect your own systems, or if you are an Admin in some organization and
you investigate the systems and networks you are responsible for, then all is well.
However, if you are not, and you try to do any investigation (even something as extremely simple as a portscan)
on systems or networks you are not responsible for, then this is most often considered to be illegal.
Even if you would have "good intensions", in effect, you "have a lot of resemblence" of a hacker.
This is not to be taken lightly. Many countries have quite some severe penalties for such actions.
Essentially: if it's not yours... keep out!
Lastly, I need to apologize for the very simplistic pictures in this note. There are many professional figures
on the internet, but it's not always clear which are "free" to use, so I created a few myself. Don't laugh ;-)
Let's review these notes then.
Main Contents:
Section 1. A few notes on DEP
Section 2. A few notes on ASLR
Section 3. A few notes on SEHOP
Section 4. A few general guidelines
Section 5. A few notes on Enummerations and Port scans
Section 6. A few notes on Windows applications
Section 7. A few notes on Legacy DCOM Security
Section 8. A few notes on .NET / WinRT Security
Section 9. A short study on a few older and well known exploits on Windows
Section 1. A few notes about "DEP".
Supporting "Data Execution Prevention" (DEP) was introduced in XP SP2 / Win2K3 SP1.
Essentially it is a technique which prevents code injected or sprayed in datapages or heaps in memory,
that it gets executed. This is so, because those pages are simply flagged as non-executable.
Most hardware as of 2006 will have cpu's with the socalled NX (NoExecute) support, which forms the basis
for hardware based DEP. If the OS supports this facility, then DEP becomes a reality on your system.
There also exists a software based DEP too, for systems without NoExecute support, but this is of a lower
degree than hardware based DEP.
However, even if hardware based DEP exists, you can instruct Windows to behave according to a number of different policies.
You can "quickly" check the current policy on your systems by using the following "wmic" commands,
using the (cmd) command prompt:
C:\> wmic OS Get DataExecutionPrevention_Available
Output: TRUE
C:\> wmic OS Get DataExecutionPrevention_Drivers
Output: TRUE
C:\> wmic OS Get DataExecutionPrevention_SupportPolicy
Output (for example): 2
The first command actually only checks if DEP is "available", which is almost always true, so this is
indeed a trivial exercise.
The third command might have some more value: it shows the current policy on your systems:
- 0: Always off. No DEP is in effect (you can play all "games" and programs not blocked by DEP).
- 1: Always on. DEP is ON systemwide.
- 2: OptIn - DEP is ON for Windows processes.
- 3: OptOut - DEP is ON for all processes. But you can create exceptions for certain programs.
You should not be happy if you see 0,1,2. In the unlikely event you see those values, then switch to policy "3".
It's likely it requires a reboot.
To change it:
You can do that using various ways, depending on which OS you run. In some cases, rightclick "Computer"
and choose "properties". Then search for advanced settings and search for "DEP".
Or: use Control Panel -> System -> Advanced Settings -> Performance Tab -> DEP Tab.
Fig 1. DEP policy "3": DEP is ON for all processes. But you can create exceptions for certain programs
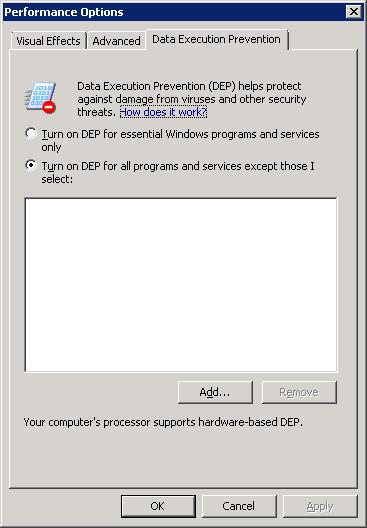
If changed to "3", then you might see that some (older) programs can not run (or install) anymore.
But DEP is quite "old" and well-known by now, just like for example "signed dll's" are, so manufacturers should
know about it too and they should have updated versions.
⇒ Essentials of section 1: switch DEP to Policy/Level 3.
Although you now have DEP globally enabled, it is still possible that some programs have been compiled (linked actually),
or "mitigated", for not using DEP. For such processes, DEP is effectively "off". That's not good ofcourse, but regrettably
this flexibility is build in Windows systems.
Notes:
(1): The DEP Policy can be seen in the registry too, in:
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control]
Where the record "SystemStartOptions"="/NOEXECUTE=OPTOUT" should be visible, which is Policy "3".
If instead you see "OPTIN" (Policy "2"), change it like described above.
(2): Note from figure 1, that usually "hardware based DEP" is in effect, as it should be.
Section 2. A few notes on "ASLR".
2.1. What is "ASLR"?
Since Vista, ASLR or "Address Space Layout Randomization" was implemented in Windows for the first time.
But it does not mean that it is active, per default, for every process.
Formerly, when ASLR was not implemented, you could place a fair "bet" where program modules
would be loaded in the address space of some process.
This fact could be exploited by malware to inject code, or change pointers to other malicious code.
"Address Space Layout Randomization" is a technique to randomize the offsets of the position of
headers, the executable, libraries, heaps, and the stack, in the process's address space.
This makes it much harder for attackers to change pointers or insert shell code.
However, if the code cannot handle this, it will crash.
The algolrithms vary among Windows versions. It can be surely said that Windows 8 and Server 2012 have more tougher
implementations (including other features), so "security wise", they are probably the best Windows versions yet.
But we must remember that any defense, including ASLR, might be broken by clever research.
Since DEP, ASLR, and others, exist in modern Windows environments, you might even say that XP and Win2K3
are actually "dead versions", not to be used anymore in business environments.
I do not want to give the impression here, that ASLR is "great" or something. Far from it.
However, it's another level of defense, and it's probably best to let it work for you.
However, ASLR can disrupt "honest" programs as well, especially if it maps (or tries to map) a shared memory object
accross various processes of the same program. Or, handles to objects cannot be found any more etc..
So, if the code is not compatible, or want to have too much control on it's own, it may crash or stop responding.
This is why modern programs should mark themselves as candidates for ASLR, by setting a certain bit (0x40)
in one of the PE header fields.
It's easy to find if a dll or executable is ASLR compatible, using the Sysinternals process explorer, or dump
the header of a dll etc.. etc.. We will see about that in a moment.
On the (somewhat) "darker" side, some developers like to know where certain modules are loaded at all times
(for various purposes), and have various ways to disable ASLR, or, if they lack permissions, they advise to disable it.
This is ofcourse quite absurd, and no sane Admin will ever accept any advices to lower security.
It's true that a property called "mitigation" can determine, on the process level, if ASLR should
be "on" or "off" for that particular process. So, a developer can choose, in principle, not to use ASLR at all when
creating a module.
This is just one reason why you should always choose for known trusted software, and not use anything else.
Is there any "system-wide" setting for ASLR, just as we have seen with DEP in section 1?
Not a very obvious one, I am afraid.
Vista Sp2, Windows Server 2008 (R2), Windows 7, and later, have ASLR enabled by default, although only for those
executables and modules which are specifically linked (development stage) to be ASLR-enabled.
As said before, it's possible to scan executables and modules, if ASLR is "on".
Ideally, you would find that all user processes would be ready for DEP and ASLR. However, this is probably not realistic
since so much legacy software still goes around.
But some applications really should be like the Microsoft Business applications (Exchange, SQL Server etc..).
In a later section, we are going to try to find out if modules are properly "signed", and if they support modern security features
like DEP and ASLR. If they do not, you can evaluate if you want to keep them,
or put the associated software on the list of candidates to be removed at a convienent moment.
2.2. Simple graphical ways to see your processes and if "DEP" or "ASLR" is in effect.
Everybody knows the standard graphical "Task Manager" of Windows. If you start it, notice that from the "options" menu, that you are able
to add "columns". Try that and search for DEP. It should at least be possible to choose "DEP" as one of the columns to add.
Then watch the process list again.
Fig 2. Task Manager, showing which processes fall under "DEP".
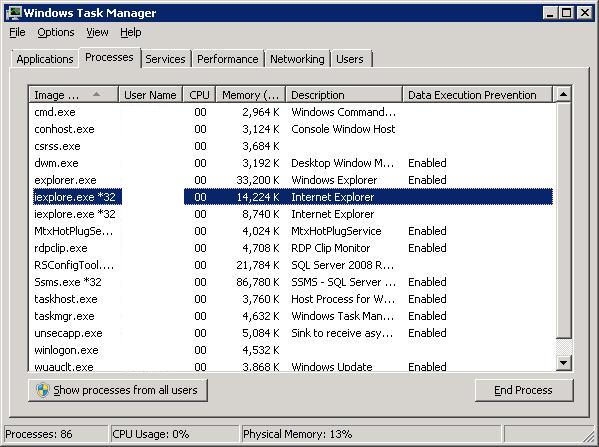
Even with this standard tool, it is easy to list processes which does not use DEP.
Finding which processes uses ASLR or not, is easy as well. It's best to use a real "Process Viewer" for this purpose.
Such can be downloaded, from trusted sources. I recommend using both of the following tools:
- Process Hacker, which you can download from "http://processhacker.sourceforge.net/".
- Process Explorer (or viewer) from the Microsoft "sysinternals suite", which you can download from "http://technet.microsoft.com/en-us/sysinternals/bb842062".
It's best to download both. They are easy to install. Process Hacker is just one utility, focused of viewing processes and
their childs, resources in use, and all sorts of properties (like DEP and ASLR).
Although the name "Process Hacker" could have been choosen better (I think), it's really quite good and trusted software.
If you install it, it's probably best to do the "minimal install".
The (Microsoft endorsed/supported) "sysinternals suite", is actually a collection of amazing tools.
In the following I will use "Process Hacker" to show processes, and we can easily find out which use ASLR and which do not.
If you do not like "Process Hacker", you can easily switch to the "process viewer" for the sysinternals suite.
After starting the utility, make sure you add the right columns so that we can view the ASLR and DEP status as well,
as shown in figure 3.
Fig 3. Adding DEP and ASLR columns in "Process Hacker".
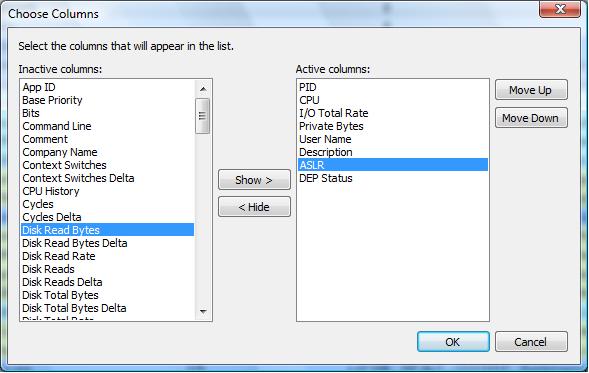
After adding both columns, you should see a screen similar like shown below. All sorts of interesting facts are shown, but here
we should focus on the DEP and ASLR properties. As you can see, it's easy to find programs which don't use DEP and/or ASLR.
You can do pretty much the same with the Process Viewer from the "sysinternals suite".
Fig 4. Viewing processes and propeties.
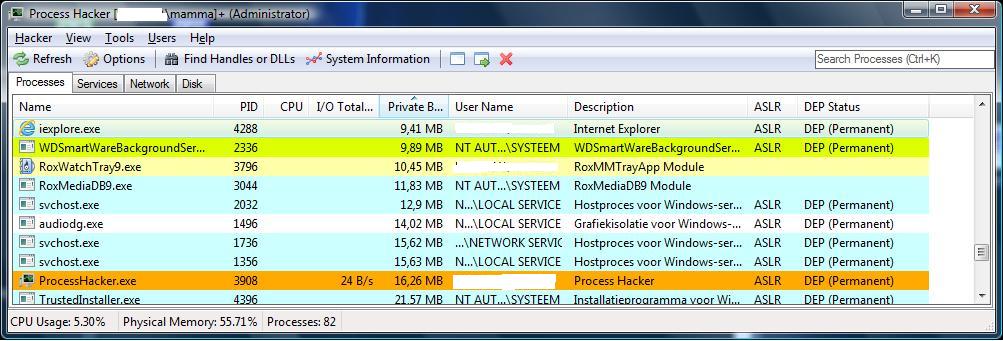
You might not be very eager to use this sort of software on Server machines. Especially if it uses kernel-mode driver(s),
which might bypass the usual API's.
In a way, you are right. You might consider to use them occasionally, just to get a list of software, and the status of DEP and ASLR.
It's reasonable to use Process Hacker, if you choose the minimal install, without installing any service.
You can also just stick to the "sysinternals suite", which is endorsed by Microsoft, and should be safe.
2.3. Automating listings of questionable programs.
Using utilities interactively is one thing, but an automatic scan (once in a while) on possible questionable processes, which don't
use ASLR and/or DEP, is much better.
I'am in the process of creating such a procedure. Once an acceptable form is found, you will find it here.
2.4. Microsoft's EMET.
Microsoft has put a free "toolkit" available, which can help to make legacy programs to be more robust, in the sense that
a "mitigation" takes place before program launch. So, features like DEP, ASLR might then work for them too.
In a later section there will be more details on "Enhanced Mitigation Experience Toolkit" (EMET).
⇒ Essentials of section 2: Try to have ASLR enabled programs as much as possible.
However, some honest, older (or even recent) programs, will not use ASLR.
Section 3. A few notes on SafeSEH and SEHOP
Up to now, two Windows security features have been touched in this note:
- "DEP", which means that data pages (like heaps) in memory will be flagged as non-executable (see Section 1).
- "ASLR", which means that the addresses of program structures in memory, will be randomized at each boot (see Section 2).
A Windows developer has a certain amount of control on the fact if DEP and/or ASLR is "on" for his/her modules.
By using certain options when linking the software, the modules might gain the means to mitigate it's capability
to cope, or not to cope, with DEP and/or ASLR.
This then will act as an "override" for a default setting, like a system-wide DEP Policy level 3 setting.
Normally, Admins do not often "ask" manufactures or developers if the software is ready for DEP/ASLR.
Usually, software is selected by other people, where business requirements are an important factor.
Also, many packages were inhereted from the past too. Etc.. etc..
So, does the discussion about DEP/ASLR (and other features) have any relevance at all? I think, with many others, that it really does.
The more software is ready for modern security features, the safer your systems will be.
A similar thing holds for something that's called SEHOP.
Essentially, the Microsoft SEHOP implementation is relevant for x86 systems only, or for 32 bit apps on x64.
So, for x64 systems you might not worry about SEHOP, however, the discussion below might still be of interest.
SEHOP is short for "Structured Exception Handling Overwrite Protection". It's mentioned in this note, since it's a feature that
can be enabled or disabled in modern Windows systems, so it deserves our attention.
That the analysis of a "program" is pretty complex, is evident. However, on a highlevel view, you can say that there is always
a "stack" involved, containing variables and functions. One important function of a program is "error handling", or "exception handling".
If some exception condition is "raised", some function in the stack should cleanly deal with this error. Usually, the resulting action
is notified to the next level of modules, possibly all the "way up" to the interface the user is working with, and an
error is displayed. So, in such situations we actually have a "Chain" of exception handlers.
Now, it's possible that some mechanism has led to an alteration of an address in the stack, which origininally was
a pointer to an exception routine, but now effectively is a pointer to malware.
So, if an exception is raised, like a buffer overrun or other, control is transferred to the malware code.
Ofcourse, this is quite bad.
Since Vista, the problem has been addressed using SEHOP, meaning that the chain of exception handlers is checked first
before transfer of control. So, the addresses of all handlers at "higher levels" should be in the chain, untouched.
This makes it much harder for an attacker, to reroute transfer of control by just altering a pointer in the basic stack.
If the other handlers cannot be found in the "chain", the exploit will not work anymore.
Ofcourse, this is a much simplified explanation, but I hope it's a bit clearer now.
SEHOP is a feature that was (seriously) implemented after the XP/Win2K3 era, so, as already was stated in section 2, this makes XP/Win2K3
even more "unusable".
However, even with modern systems like clients as Win7, or Servers as Win2K8(R2), we are not completely "done", and indeed,
we must take notice of this:
- Modern Server systems like Win2K8(R2) have (probably) SEHOP enabled by default.
- Modern client systems like Win7 have (probably) SEHOP disabled by default.
- Some software need to be relinked again to make them use SEHOP. This works for x86 platforms.
- Some software might benefit from the Microsoft EMET kit (later more on this).
It's indeed possible that some (legacy) software cannot cope with SEHOP.
On x86, a registry key gives you "some" means for a global way to enable SEHOP, or do it on a "per process" basis.
So, for example, on Win7, you might inspect:
-Global setting:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\kernel\
DisableExceptionChainValidation
.with value "1" meaning SEHOP disabled
.with value "0" meaning SEHOP enabled
-Per process (for example "abc.exe"):
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options\abc.exe]
"DisableExceptionChainValidation" 0:enabled, 1:disabled
⇒ Essentials of section 3: Try to use SEHOP enabled programs as much as possible.
Section 4. Some general guidelines.
The guidelines below are quite trivial. Maybe you agree on all of them, or maybe you think one or two
don't work for your situation. Or you might even disagree on those point(s). If so, can you explain
why you disagree?
- If possible, enable "portsecurity" on your network, so that only selected MAC addresses (networkcard address) can be connected
to physical network ports in your network. This is often configured at the "switch level".
The larger and more "open" your physical environment is, the more this guideline makes sense.
- In a Domain, services often use "service accounts", which are actually normal domain user accounts as well.
Make sure they are not member of AD groups with elevated privileges, like Domain Admins.
It's certainly worth scanning your service accounts for membership in highly priviledged AD groups.
That in some situations, a service account is member of a local Admin group of a member Server, is sometimes a requirement
of some application. This is absolutely undesired as well, but regrettably it's often a fact.
- Minimized the exposed "surface" of any machine, Server and Client, meaning:
=>Only enable and use services which are absoluted needed for this role.
=>Only install roles and features which are absoluted needed for this machine.
=>Enable the Windows internal "Firewall" on all machines at all times. Create inbound rules for needed ports only.
=>Only create CIFS/SMB shares as is needed. Consider to make them "hidden" using the "$".
=>Get rid of the "everyone" "group" on any volume on every Server. It's not needed.
=>If possible, get rid of any (enummerating) "Browser" services of your systems.
=>Anti Virus is needed on all machines, even internal Servers. Do you really take that seriously?
=>Harden any Server and client as is suggested in all sections of this note.
=>Evaluate group/Domain/OU policies again. Sometimes, nasty surprises comes to surface.
- Make an effort to inventory and correct all application config files which expose accounts, and even
may carry "clear text" passwords.
These could be .ini, .conf, .cfg, .xml files and many more. You might confront a manufacturer with this ill-practice,
and demand a solution.
- Services which are "public" might be weaker than you think. For example, many websites really have vunerabilities like for "SQL injection".
Are you sure that all you publicly exposed sites are sufficiently "hardened"?
Hardening traffic to/from the "external world", really requires special knowledge and actions, even beyond
what Admins usually apply in internal networks.
- VPN connections from Remote users to the business network are generally percieved as "safe". However, vunerabilities
have regularly been found with several VPN solutions. The current state of your particular VPN solution, should be investigated.
Sure, this info is almost nothing. But it's not a false alarm, so make sure it is not underestimated.
- Restrict usage of usb sticks and other portable media. It's not for regular users, certainly NOT for visitors (like developers etc..),
no matter how "handy" this stuff might be.
- Special attention must be given to any service or application using dcom and related technologies.
The security model used, is often not very transparant to SysAdmins.
Often, the defaults that a manufacturer presents you, fall short in good security practices.
In one of the next sections, I will try to get this "opened up" a little, which is actually a real challenge for a certain Albert.
- A properly designed architecture of business systems, often use "rings" using Router-Firewall/Switches using L3/L2 networks/segments.
The core systems are centered, and are "open" only for certain accounts and services. More mundane systems
are on "outer" rings. If you have such an architecture, that would fine. If not, you could think of (gradually) correcting it in time
using vlan and other technologies. Even on a logical level, you can achieve such a state using "policies".
- For very critical systems, you could consider getting rid of Windows altogether! No.., thats really a silly joke.
Seriously, You could consider "Windows Server Core" systems, which only can be locally managed using a "prompt"
(cmd, Powershell) while such systems misses all those dll's and subsystems which are needed to support a graphical interface.
So, it's exposed "surface" is substantial less compared to it's "graphical" sisters.
Still you can use the common graphical tools from some management Server or workstation, to manage the system or some
application running on the "Core" system. Another positive aspect is that "Core" requires less patching.
I think Core is way "stronger" and I believe that full-time "official" security experts will agree on this."
- If still needed: Implement a proper level of auditing. Yes, it's a very general statement, but you must invest (probably a lot of) time
to get this up and running. It's also a bit to protect Admins from e.g. "sharky" auditors saying "Why was this not properly set up?"
Depending in what business you work in, and in which country, failing to have proper auditing might have serious consequences!
Indeed, "security" has become "big business" and all sorts of auditors and specialized firms roll out the assembly line at a high pace.
Nowadays a lot of protocols and rules are in place, specifying what must be audited and what must be tested on a regular basis.
For your line of business, possibly some "standard" is published too. People just assume you know that.
⇒ Essentials of section 4: Seriously evaluate all of the above. Maybe not everything is great, but you know...
Section 5. Some notes on Enummerations and Port scans
⇒ "Enummeration" is usually to be understood as any action to aquire an expanding listing of information
on resources as shares, open ports, accounts, services, computer names, and all other sorts of sensitive information,
usually done by a person (or process) who (or which) is not a trustee supposed to have access to that information.
As simple example: suppose there is a "visitor" on the premesis, who is able to plug in his/her laptop in a business network, and is not
authenticated in the proper way (like an AD/network logon), and not withstanding the lack of proper authentication, still is
able to retrieve information like shares, open ports, accounts etc.., by using regular commands or other stuff like specialized tools.
Typically, in such cases, the person (or process) aquires a growing list of "facts" which can "help" in determining the next step
in finding the weak spots in any aspect of the system as a whole.
⇒ A "port scan" is nothing more than an action to find out which machine(s) have udp/tcp "ports" open,
and so it might be possible that services are "listening" for requests on those ports.
Thus, a scan might be fully "harmless" because it's performed by an Admin, just to test the network if it is secured properly.
Or, contrary, a person (or process) might use a scan for enummeration of open ports, and perhaps try to spot and utilize
a weak spot to exploit the system (deploy a payload, theft of data etc..)
⇒ "Finger printing" is a sort of enummeration in fifth gear. Here, the "white hat" hacker, or "black hat" hacker seeks
information from any source he/she can get. So, for example, if using a packet analyzer, if a packet is captured showing only a logon banner
where the OS version is presented, that could be a valuable piece of info. So, in this procedure, what is often seen as "harmless" info,
might not be harmless at all, since the attacker stems immediately his/her next steps according to the info found.
So, in the example of a logon banner, if it would show an OS build number, then immediately is known to which unpatched
vunerabilities this OS is sensitive for.
⇒ Others: Since there exists many IPC occurences (one one system, or between systems), many "endpoints" can exists
which can be exposed using regular commands or specialized tools (e.g. rpcdump).
So, "enummeration" (or getting systeminfo in an unauthorized way) might take use of several means like ordinary commands, or a "portscan",
or other means.
5.1. A few simple notes on a portscan.
There is a lot of technology involved here, and not all Operating Systems have the same means to counteract "nasty scans".
You can easily check yourself "manually" if a port is "open" on a local or remote Windows machine, by using a utility like "portqry". This was a common tool
in Win2K/Win2K3. You could check if for example the range of ports "22:80" on Server "starboss" is "open" by using a command like for example:
C:\> portqry -n starboss -r 22:80
You would then see a listing of "non-listening" and "listening" ports in the range 22-80.
Anyway, here a full TCP session was established (between you and starboss), using the regular full "three way TCP handshake".
Ofcourse, this sort "portscan" takes a lot of time, and might even be logged on the Server. So, it's not very efficient
from the viewpoint of malware or a Hacker.
Note: the "portqry" command is rather old (obsolete perhaps), but a few modern equivalents we will see later on.
Smarter and faster portscanners, which will try to avoid detection, often make smart use of some special fields in the TCP header.
Take a look at figure 5. Here you see the first layers of a network packet, with emphasis in the IP and TCP (v.4) layers.
Fig 5. Addresses, ports, and special fields in tcpip (v4) packets.

The "yellow" coloured fields takes part in "addressing" like the MAC addresses, the source and destination IP addresses, and the source and destination ports.
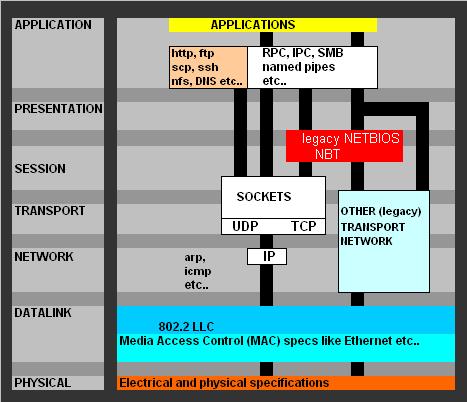
It probably can't hurt to have also a "high level" overview of common protocols, set against the 7 OSI layers,
to which we may refer sometimes. For example, note from figure 6, that we can see that "SMB" can use sockets/tcpip "directly,"
(which is the modern way), instead of using the Netbios layer (which is the old NT way, for example for naming and session services).
Fig 6. High-level overview protocols.
Refer to figure 5 again.Note that there exists a lot of other fields as well in the TCPIP v4 stack. Especially the 6 "green" fields (like "SYN", "FIN" etc..)
are often utilized by smarter portscanners to avoid a full TCP "handshake", and to avoid logging and detection.
=>Usually, a portscan using regular system commands or tools, uses the normal TCPIP stack that's build into the OS, and thus a three way handshake
is very likely to happen, espescially when the machines "think" an ordinary connection is being build up.
=>However, classically, if a utility can "build" the packet by it's own, or is able to alter it before it's send, it's possible to utilize
special flag fields in the packet (the green ones) which modifies the regular behaviour. This actually is "as designed" in the protocol.
So, a scanner might use the "FIN" field first. The result might be, that the Host responds with a SYN-ACK if the port is open.
If it is closed, it responds with an RST. This is not a full connection oriented session, so it might be "stealthy" and quick.
Using various methods with the"FIN" and/or "SYN" and/or "ACK" flags on, or possibly all "NULL", or possibly all "on" (xmas), a scanner might deduce if ports are open,
closed or filtered, depending on the Host OS and the (optional) firewall involved.
There are more "techniques" than the ones touched above. Other fields might be "misused" as well.
Note: In a normal "session setup" or "tear down", the use of SYN, ACK and FIN flags are absolutely normal. However, if you start with FIN,
or all flags set, or none set, or another combination, you obviously do not use a regular session setup.
Now actually, the responses a scanner get's back, also depends a bit whether the OS involved is fully RFC compliant or not.
Windows is not perfectly RFC compliant in some details, so any scanner should have minor difficulties in reaching perfect "conclusions".
However, many wellknown tools as "nmap" and many others, are remarkably successfull in establishing listings of open/closed ports
without completing a regular TCP connection, and thus it might avoid detection.
You might consider downloading and installing (classical) tools like "nmap" or "hping", on a test workstation, and explore it's capabilities.
There are many free portscanners, or some with an evaluation period. A really extremely simple one is "Advanced Port Scanner (1.3)" from "Rapid"
which is very easy to install and use. It can show you open/closed ports of one or more machines in your subnet.
So, what is there to learn from this?
(1). Smart scanning tools exists (which, in some cases, "might" even fool an OS or firewall), and which can ennumerate on open/closed ports.
(2). At least we know that we should try to minimize all possible ennumerations on ports.
⇒ Essentials of section 5.1:
- If possible: consider configuring a service to listen on another port from the "expected" default one. For example,
if an application standardly uses the (expected) port of 1521, you might consider to configure it for, say, 5232.
- Disable/uninstall any unneeded service/application that opens a port.
- Enable the internal Windows firewall at all times, on all machines.
- If possible, don't use the {any IP}-{any IP} if you create a rule.
If you know where clients are located, name those subnet ranges in the rule.
- Only configure specific "open" ports as is neccessary, and no more.
It's certainly not always "easy" to implement all of the above on all systems.
5.2. Using regular commands to view connections and ports.
Important: In this section, we asume that we consider "internal networks" only.
So, for example, if you see a statement like that a port like 445 can be opened for certain Servers,
in order to make "SMB over TCPIP" possible, and to serve AD traffic, it only applies
to internal networks (like LANs) ofcourse, isolated from "public" networks.
So, All ports mentioned in this section must be "off" or "closed" fully, for any firewall which
touches on DMZ or public networks.
5.2.1. The "netstat" command:
Your Windows OS already have some tools aboard for monitoring network connections, and the status thereof.
For example the "netstat" command is a great utility, which output is quite selfexplanatory, except maybe for the status
of the connections.
Actually, the majority of TCP applications are "socket based" applications. This means that a connection is opened from, say, a client app
to a Server using "Server IP: port number" which is "part" of what people call a "socket".
Server and Client applications can influence the state of the connection, which can have a number of values.
The exact details can be found in an "TCP state diagram", or TCPIP book, and it's not really helpfull to repeat that stuff here.
We just concentrate on a few of the main "status" values you can see using Windows tools, like "netstat".
- ESTABLISHED: An session is established. Data transfer may proceed
- LISTENING: The Server has a passive openend port, and is ready for connections to established.
- CLOSE_WAIT: This indicates a passive close. The Server just received first FIN from a client, so
the other side has closed the connection. The Server still has it's socket open. This could be due to various reasons.
- TIME_WAIT: The Server closed the connection. However the socket is in the TIME_WAIT state, which means that
(rarely) delayed packets can be assoiciated with that socket. If nothing happens, usually the connection is gone
after 4 minutes (on Windows and most other platforms).
There are a few more status values (like SYN_SEND), but since connection setups/tear down are fast, you won't see much
of those.
The netstat's output usually is quite large (lot's of rows), but some rows are repeated and some rows are
only due to local connections (only on your machine), and this is why correctly interpreting the results is not easy.
First I would like you to try the "netstat" commands below, and watch the output, and try to observe the differences.
Ofcourse you can just "copy/paste" the commands in a command prompt window.
It's advisable to start a prompt window first with elevated privileges (Run as Administrator).
C:\> netstat -a
C:\> netstat -a | find "LISTENING"
C:\> netstat -a | find "135"
C:\> netstat -a | findstr "LISTENING|ESTABLISHED" # Depending on version: use a "space" or "|" to search on multiple strings.
C:\> netstat -a | findstr "135 137 138 139 445"
C:\> netstat -anop TCP
C:\> netstat -anop UDP
C:\> netstat -abf
C:\> netstat -abf > out.txt # to redirect the output in the "out.txt" file.
- Note that "netstat -a" just shows "everything".
- Next, using "find" or "findstr" you can "filter" the output on any string of interest like "LISTENING",
or some portnumber like "135", or some other string.
- Using "-p" you can concentrate the output on a certain protocol like TCP or UDP.
- Using "-n" shows Process ID's (PIDs), while "-b" (modern versions) shows the executable names.
- Using "-abf" (on modern Windows versions) shows you the local executables (.exe) who are involved in the connection,
as well as (if possible) the fully qualified name of the remote host this executable is connected with.
- And, if you "redirect" the output, using ">", you can place that output of any netstat command to a textfile
which you study at a later moment, or save it to disk if there was any need for saving it.
Now, what might you find using netstat commands?
=> Regular remote connections:
First of all, on a Server machine, you might see (lots of) "normal" connections, like in this example:
..Proto..Local Address......Foreign Address......State...........PID
..TCP....10.10.10.15:1433...10.10.20.89:2391.....ESTABLISHED.....48652
..TCP....10.10.10.15:1433...10.10.20.31:4103.....ESTABLISHED.....48652
..
Here, we have a local process with PID 48652, which happens to be SQL Server, and possibly many remote clients with different IP's
and different ports, have connected to "10.10.10.17:1433".
So, defenately, the local port "1433" is open, and should be open, otherwise clients cannot connect to SQL Server.
Since "1433" is the default port, it might have been better to let SQL listen on a non-default port.
=> Regular local connections:
..Proto..Local Address......Foreign Address......State...........PID
..TCP....127.0.0.1:49264....127.0.0.1:49276......ESTABLISHED.....2732
..TCP....127.0.0.1:49269....127.0.0.1:49264......ESTABLISHED.....1712
..
You may not see such output on your systems. But some systems do. A few apps use sockets too for local connections.
Since 127.0.0.1 is a "local" address, we see here "local - local" connections. This is nothing to worry about.
If you see them, you can use other netstat switches (-b) to see the executables involved.
Or, using the PID, just use:
C:\> tasklist | find "PID"
=> The "strange" connections:
On many systems, netstat listings will show the following lines too, which a lot of folks might find pretty remarkable:
..Proto..Local Address......Foreign Address......State...........PID
..TCP....0.0.0.0:80.........0.0.0.0:0............LISTENING.......4
..TCP....0.0.0.0:135........0.0.0.0:0............LISTENING.......744
..TCP....0.0.0.0:445........0.0.0.0:0............LISTENING.......4
..TCP....0.0.0.0:808........0.0.0.0:0............LISTENING.......1928
..
First, if you see a local address like "0.0.0.0", it means that the local application will listen on all local interfaces.
So, it means that port behind 0.0.0.0 is listening on all 'network interfaces', that is, all your network cards.
Lets walk through to the most important entries:
- A: the "0.0.0.0:80" local address/port.
A local address as "0.0.0.0:80" might strike you as quite absurd once you have figured out what application or service listens on it.
In this case, we see a PID of "4". Using the "tasklist" command it's easy to find out that it's the SYSTEM process.
This could amaze you, since that looks a bit dangerous.
Actually, it's the kernel mode part "http.sys" of the embedded http Server which is active in many Windows system.
If you want to know for sure:
If you shut IIS down, such a record as is listed above, is probably gone. Sometimes "0.0.0.0:80" might also be due to a "Report Server" process,
since that one might use the embedded http Server too. If you use SSRS, you might stop it for a moment, and see if the "0.0.0.0:80" entry is gone.
- B: the "0.0.0.0:135" local address/port.
In this example, we see a PID of "744". On other systems it will be another PID ofcourse. In this example, the service just "happens"
to have a PID of 744. Using the tasklist command again:
C:\> tasklist | find "744"
svchost
C:\> tasklist /svc
..
svchost.exe 744 RpcEptMapper, RpcSs
..
So, this port is used by a "sort of" listener/mapper for RPC connections. Actually, the mapper will assign higher portnumbers
to rpc applications, before they start the communication. The 135 is only used for the "listener/mapper" itself.
This "Endpoint Mapper" is actually the "RPCSS" process on your Windows machines.
Maybe, on your machine, you might have 8 or more of such "0.0.0.0:port#" entries in a netstat listing.
It's not very usefull to discuss all possible "variations" of such entries in this note.
While it was indeed possible to kill the 0.0.0.0:80 (if you do not need IIS or SSRS and that sort of apps), contrary, with RPC, it is a bit more "involved".
Many modules in Windows use "RPC" for local and remote communications. If RPC is down, Windows is crippled.
This is certainly more so for Domain machines (workstations, member Servers, DC's).
Remote Procedure Calls (RPC) are one of the foremost Inter Process Communication mechanisms in Windows (and other OS'ses).
- C: the ""0.0.0.0:445" local address/port.
Quite some time ago, in old Windows versions, Netbios over TCP (NBT) was a very common stack for network communications, like
file- and printer sharing. Certainly where "shares" were involved, SMB using NBT was very common. The NBT stack used ports
137, 138, 139. The NETBIOS "stuff" was actually created a long time ago, and some people say
that it should have be declared "dead", many years back. However, NETBIOS seems to be "unkillable" and it is still used
in various parts in Windows and applications.
So, the ports 137,138,139 were reserved for the "classic" NBT services. Over some years, it was more and more reckognized that
vunerabilities existed (like relatively easy enummeration) in this stack, so many people were motivated to shield off those ports
using firewalls. However, it was an important functionality in Windows.
In modern Windows versions, you will not see any listeners on 137/138/139 anymore. Since XP/Win2K3, SMB over TCP was implemented,
without NetBT. For this purpose then, TCP port 445 is used. This is often called "Microsoft-DS".
So, if you have implemented any sharing services implemented, expect to see the port 445 in netstat listings.
It is commonly understood that it's acceptable to have 445 opened in a private LAN only, on Servers which need it.
But it cannot be exposed on any public interface. So, all ports in the range discussed must be blocked in firewalls.
- D: All other "0.0.0.0:port#" local addresses needs to be investigated.
Using the PID and "tasklist", you can find which services are listening. However, it might be impossible to shut those down,
since those services might be essential services of this system.
So, a core question is: can those listening ports "hurt"?
In private LANs it is pretty much unavoidable to have the RPC listener on 135, and SMB and other Services on 445.
Ofcourse, in all of the discussions above, we assumed your internal machines are never exposed to public networks.
Note:
It might be viewed as a real pain, but Active Directory communications like replication (using dynamic RPC and SMB etc...),
needs more open ports.
It's true that even for internal LANs, with firewalls in place, quite a few more ports need to be opened in order
to make inter Domain Controller traffic possible. Since AD replication depends on LDAP, RPC, and SMB,
in the "default" situation, extra ports must be enabled. This is true with the default "dynamic" RPC situation.
So, (at least) this should be open too:
- TCP 135 RPC Endpoint mapper
- TCP,UDP 389 - LDAP
- TCP, UDP 88 - Kerberos
- TCP 445 - SMB over TCPIP
- TCP, UDP 53 if DC's are DNS servers too.
Since AD has so many DC roles, features, compatibility modes, it "may" even "turn out" that this must be opened too:
- 137/tcp, 137/udp - Netbios naming service.
- 139/tcp Netbios session service.
In such situation, we end up to have all this NETBIOS stuff back again.
So, in an AD network, is the ideal of having the lowest open ports and listeners, possible?
However, there are a few methods to try to lower the damage. If this is of interest, you might take a look at:
MS Technet: Active Directory Replication Over Firewalls
5.2.2. Some other commandline utilities to get info:
- 1. standard Windows, or Resource Kit, tools:
netsh
wmic
rpcdump
rpcdiag
older: using VB scripts and comparable scripting technology
newer: Powershell scripts
(Still thinking about what could be usefull here...)
- 2. Other commandline tools:
(Still thinking about what could be usefull here...)
Essentials of section 5.2. These are rather trivial indeed:
By using "netstat", and other commands, and portscanner, for an internal network, the following holds:
- Internally, check any local service/app which uses "0.0.0.0:port#" if the port# is not 135,445.
- Identify any port not needed to have a listener on.
- Identify any interface not needed.
- Identify any IP subnet not needed to connect to any serving machine.
5.3. Using some graphical tools to view connections and ports.
This really is a simple section. There are many graphical tools out there which can show you open ports and/or connections,
with no more than just using a few mouseclicks. Some tools can scan all hosts on a local subnet, while other tools work on the local Host only.
There are the (more or less) "classical tools" like nmap, zenmap, hping, nessus and a few more. But there also exists a few very accessible tools,
which require hardly any preparation, or study.
The following tools are indeed that simple, and are (I think) quite good for Home users too.
5.3.1 Simple portscanner, e.g. from Radix, for local and remote machines:
You might try the portscanner from "Radix". If you would have a small LAN, and you like to see a listing of open ports
per machine in a subnet. Just type in a range of Host IP's, and click "Scan".
Fig 7. Using a Simple portscanner.
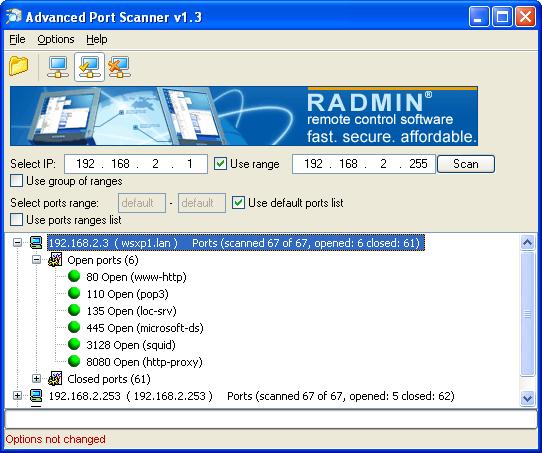
In the figure above, I see the open ports on one of my (home) machines, which I expected to be open.
Although such simple scanners are not perfect ofcourse, it is indeed true that you can get a very quick and compact listing
of open ports. It's so simple, compared to the (sometimes) cumbersome output of commandline tools.
Note that the tool is not only able to scan the local machine, but other Hosts too.
5.3.2 Simple TCP viewer (local Host only):
For showing a graphical view on what connections are established on your local Host, one great tool is "tcpview" from
the "sysinternal suite".
You do not need to install anything. Just copy "tcpview.exe" to an appropriate folder and start it up.
Fig 8. Using a Simple Local TCP connection viewer.
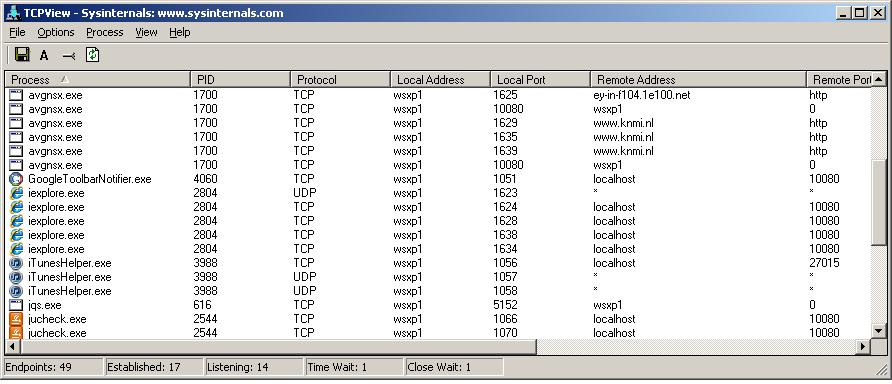
As you can see from figure 8, the fully qualified names of remote Hosts might be shown, as well as many other
parameters related to connections.
The figures 7 and 8 were created on a Home PC, and not on a Server on business network.
5.3.3 More Advanced scanners like "nmap" (Remote and local Hosts):
You can download and install the (32 bit) "nmap" suite which consists (among others) the "nmap" commandline utility,
as well as the graphical "zenmap" workbench. It runs on XP,Vista,Win7,Win2k3,Win2K8 (32 or 64 bits).
Advanced scans are possible using different TCP "flags", or using "evasion", "spoofing", "data length" options and many more.
It can also perform scans with sort of scripts you have pre-designed.
Since the readme or tutorial is quite large, we mention it here for illustrational purposes only.
Fig 9. Using "zenmap" and configuring "scan options" .
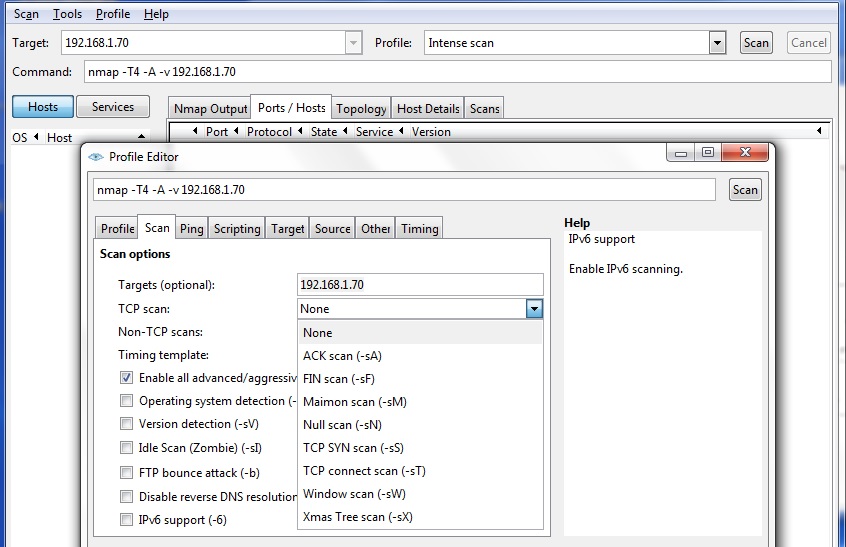
Note from figure 9, that I am able to select a FIN scan, or NULL scan etc.., just as we discussed in section 5.1.
Section 6. Some notes on Windows applications
6.1. Types of Applications:
When discussing the different types"of applications on a Windows system, there are quite few "catagories" to consider.
The following is from a "SysAdmin" viewpoint, since developers are more likely to talk about the dev environments like
C++, C#, VB, XML, XAML, Java, J2EE, EJB, Python, HTML etc..
Let's make a distinction between:
- "traditional" applications used in environments up to Win7/Win2K8 R2, and in Win8 (not the "app Store" apps).
- "app store" apps (a bit "tablet-like") interfacing with the "WinRT API" in Windows 8.
But, the situation still is that the "majority" of usage of true "office/business" applications, are still
of the types listed in section 6.1.1.
6.1.1 Regular applications up to Win7/Win2K8 R2, and also as "non-WinRT" apps on Win8:
Maybe you want view figure 10 below first.
Listing the traditional applications, found in Win2K3 (R2), Win2K8 (R2) as Servers, and XP, Vista, Win7, Win8 as clients, we can typically find:
- First of all, we have the "oldfashioned WinApi" Desktop apps, which "deal" with the well-known WinApi.
They all have basically the same "look and feel" over the years that Windows exists by now.
It's those category of applications with the typical user32 controls as radio buttons, "OK/Cancel"dialogboxes etc..
Suppose somebody creates a WinApi app, for example using VB6 (not the dot NET version), then it directly uses comdlg32, user32 and a series
of other API dll's, all belonging to the WinApi, which can be largely associated with the "csrss" subsystem.
CSRSS is short for "Client Server SubSystem".
These apps are nowadays also often called "unmanaged" code.
- The newer "Dot Net" apps (and "webservices"), uses a well defined series of class libaries.
Those apps live/run in the socalled " Common Language Runtime "(CLR)" susbsystem.
The CLR is a sort of Virtual Machine, which provides all the interfaces for such a dot NET app, to perform it's work.
So, dot NET apps are not (direct) WinApi apps. You might say that the CLR "encloses" the dot NET app.
You may visualize this as if the CLR is a container which encloses the apps, and provides services to those apps.
This is not exactly the same as "sandboxing".
Although dot NET is new compared to oldfashioned Desktop apps, Microsoft also made it possible for developers
to use existing COM code from within .NET, and the other way around.
For example, COM TLBs can be converted into .NET metadata, allowing .NET programs to treat COM components
in a way as if it was all produced in .NET. Note that DCOM will be discussed in the next section.
This way, you can question the "purity" of dot NET apps, but it was all legal and by "design".
In DOt NET, having precise metadata describing the application, is much more prominent compared to e.g. WinApi Desktop apps.
DOT NET apps have a selfdescribing "manifest" which (should) clearly define what this application needs.
So, there is (generally) no need for all sorts of wild dll's and unclear Registry entries.
As it was presented quite some time ago, you can xcopy the app from some sort of media to your system, and it
can be run without difficulties (this is somewhat "relaxed" nowadays).
These apps are often called "managed" code. "Managed Code" is code whose lifetime and execution is managed by the CLR,
and which uses selfdescribing "manifests".
Indeed, generally security should be enhanced using fully managed code.
As DOT NET uses a higher abstraction level (compared to e.g. traditional C/C++), so all sorts of physical details like
heap allocation, and de-allocation etc.., is not for the developer to worry about.
For example, a special routine, the Garbage Collector (GC), like in Java, will clear out constructs if they are not used anymore.
- As they are a bit special, we have the "Native" NT apps, which use the (true) systemcall interface directly (ntdll.dll),
instead of using the WinApi first, that is, instead of using the regular "crsss", or the WoW64 subsystem.
Almost all regular apps (like Exchange Server, SQL Server etc..) are NOT native.
So, a native application uses the functions of NTDLL.DLL directly, so a lot of "comfortable" functions which are offered
by the higher level WinApi, now must be taken care of by the app itself, like requesing a Heap allocation and deallocation (etc..),
using the functions of NTDLL.DLL.
Some Windows components themselves are called Native NT apps, because they need to activate and perform
work during the bootphase, before the WinApi is up an running.
For example, the SMSS subsystem is up quite early in the bootphase (before the WinApi)
and it checks "HKLM\System\CurrentControlSet\Control\Session Manager\BootExecute
to find modules which should run before all of the "rest" of the usermode systems are up.
Ofcourse, WinApi (csrss) itself is a native app, since it "floats" on the true fundamental systemcall interface.
- "DCOM" apps. DCOM, or "Distributed COM" applications are composed of a set of binary components, where those components may
run one the same machine, or are distributed over a number of machines.
DCOM is like COM "over the wire" (between machines). It's not dependent on a certain programming environment (like that you must
use C++ or so). COM is a specific 'object model" with clearly defined interface descriptions, which allow the objects
to communicate, using "Remote Procedure Calls". So, the underlying communication protocol is "RPC" (over TCPIP).
- "Java" applications, like dot NET apps, live in their own Virtual Machines, called "JVM's" (Java Virtual Machines).
Such a JVM is very comparable to the working of the dot NET Virtual Machine (that is: the CLR VM).
However, the Java apps themselves are a completely different "world", compared to for example dot NET apps. But, the way how the apps
(dot NET and Java) use the services offered from their VM's, are quite similar.
So, what we now have summed up are:
- old-fashioned WinApi (Desktop) apps,
- dot NET apps,
- COM, DCOM, COM+ apps,
- the "strange" Native apps,
- and Java apps.
This stuff runs on Windows 8 too. However, since Windows implemented the "app Store" and a new API (WinRT), we look at
that new stuff in section 6.1.2.
We should not think that these are always "pure" categories. For example, a dot NET developer might find it usefull
to import WinApi functions in his/her code, simply because an easy to use functionality already exists in the WinApi.
Also, it's not uncommon to use existing COM code from within .NET, with the metadata converted to dot NET metadata.
Fig 10. High-level overview API's in Windows.
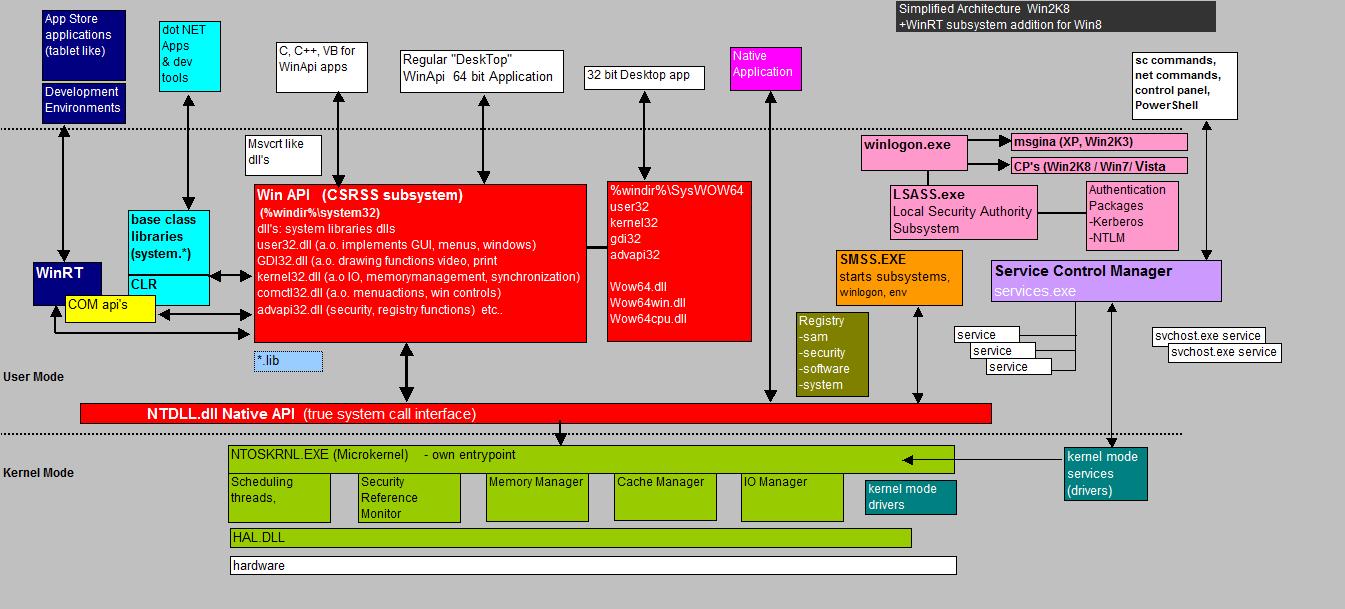
Note: figures like fig. 10 are, in a sense, "not really great". However, they provide a means to present a quick "birdseye view" on API's and Architecture.
So, this gives them some justification. But they are never fully satisfactory. Please note that the "app store" and "WinRT" API
only apply for Windows 8.
6.1.2 "Store Apps" and WinRT on Win8:
All the "traditional" applications as seen in section 6.1.1, work (generally speaking) also in Win8.
So, Desktop applications for the usual WinApi, will run too in Windows 8.
But a new additional API and application model is implemented, which set Win8 apart from the former versions.
Here we mean the "app store" applications using the new "WinRT" api. These were formerly called "Metro apps".
WinRT apps should not interfere with other running applications, because they are ran in a "sandboxed" environment.
A "sandboxed" environment "looks" like an application Virtual Machine, shielding the application, as well as restricting
the application in accessing resources like filesystem objects. For example, you can restrict an app to where it can write.
However, sandboxing is certainly not the same as what we understand to be a true VM.
The following "facts" with respect to "Store apps/WinRT" can be listed:
- They are Distributed only through the Windows Store.
- They live in a "sandboxed" environment.
- WinRT itself uses the COM API as well as the WinAPI.
- There are more restrictions possible on resource access.
- There are better facilities for permissions like for "launching" the application.
But.., the situation for what we consider to be "business" applications, is that the majority still fall in the catagories we have
listed in section 6.1.1.
The "app Store" applications are under tight control by Microsoft, so it seems reasonable to think that this type of application
using WinRT is less prone to malware compared to the traditional applications listed in section 6.1.1.
It also seems reasonable to expect that quite some business applications might shift from Desktop to "Metro Apps" in due time.
It's remarkable to see how strong WinRT depends on COM, and how the "mechanics" of both are very similar.
So, it's very important to get grip on COM & DCOM, since this helps us in appreciating security with the traditional applications as well
as with WinRT applications.
6.2. Stacks and Heaps and some system details:
Here are a few notes on system details like "stacks" and "heaps", which concepts are quite important in our study.
Modern development environments (like C#) are business oriented: the developer does not deal anymore with
heaps and stacks, in the way the traditional programmer did (like in using "C").
Even maintenance on objects and memory areas are nowadays "covered" by a Garbage Collector process, which may
destroy objects if references to the objects are zero, or it may use other "triggers" for cleaning memory.
However, even in modern environments, under the hood stacks and heaps are still used on the system level.
⇒ The "stack" is the memory set aside for variables and function addresses, for a thread of execution.
Each thread created, gets attached to it's own stack. When a function is called, a new block can be used on
top of the stack.
A stack is relatively small (compared to a heap), and is a "sort of map" of the running code, containing "pointers".
⇒ "Heap" is the usual name for the larger "free space", the memory space where dynamic objects are allocated.
File pages are loaded here, as well as programmatic "objects", and other stuff the program needs or creates.
It's much harder to keep track of used/unused blocks in the heap, compared to the simplicity of stacks.
Typically, a process has one (or a few heaps), while each thread has its own stack.
when you use a function call for a new "object", the memory for the object is allocated from the heap. However, pointers
to internal methods are "stacked" on the stack.
Normally, When a new object is instantiated this way, you will be allocating memory from the heap
but you need a pointer (sort of variable) to store the location (in the stack).
The figure below tries to illustrate the difference between a stack and a heap.
Fig 11. High-level illustration of Stack and Heap.
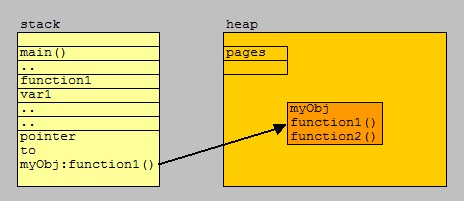
Stacks are for the small "things": variables, addresses for functions. Heaps is for the larger "things":
objects, filepages and that kind of objects.
In case of objects and that sort of "stuff": A stack "says" where the stuff is. A heap stores stuff.
A "quick note" on Program Load:
Here are a few short descriptions of a program load:
⇒ A WinApi program:
When an executable is started, a new process is created. Each process gets a virtual address space.
In this address space various things are loaded or created by Windows, before the executable can run.
Among which are:
- All Windows needed libraries (kernel32.dll, etc...)
- The executable itself
- All the libraries that the executable imports
- The Process Environment Block (PEB), which stores information about the process
- A Thread Environment Block (TEB) for the main thread
- A stack for the main thread
- One or more heaps (often one, sometimes two)
- a stack for each new thread.
Viewed from a "file format" perspective, the executable file (.exe, .dll., .sys, .drv, and others) uses
the PE (Portable Executable) header, which also carry information about the sections in other parts of the file.
In a way, it resembles a sort of index.
One important field is the RVA, or the "relative virtual address". It specifies the offset of the "entry point"
relative to the loadaddress of the file. This sort of "explains" how an executable gets "running".
⇒ A DOT NET program:
From a logical view, .NET executable is an "assembly" and is more or less a selfcontained solution.
It runs "in" the Common Language Runtime (CLR), which is a runtime environment for .Net applications.
The development environments, will take care that the source code get's build to MSIL bytecode,
which "is fit" to run in the CLR environment.
This situation is really somewhat (or quite a lot), from a logical perspective, comparable to the Java platform.
Another thing is, that the .Net programmers do not have to deal with thread management, heaps etc..
that will all be done by the .Net environment. From a hard technical viewpoint, heaps, stacks, threads
are still there, but not in immediate sight of the developer.
Viewed from a "file format" perspective, the executable file has an extended PE header, with CLR sections,
which plays a similar role compared to the traditional executables.
Certainly, a program gets it virtual address space, and the RVA again points to the entry point.
There are entry points (like importing) to .Net core files as well (e.g. mscoree.dll).
Section 7. Some notes on "traditional/legacy" COM/DCOM Security
7.1 A birds-eye view on the DCOM architecture:
7.1.1 Some general notes:
We need to have a basic understanding of DCOM before we can say anything usefull about security.
A complex technology as DCOM cannot be learned in one short "Big Bang". So, as always, by "slowly" presenting some facts
we will be able to appreciate DCOM.
The "Distributed Components Object Model", is a technology which makes it possible that COM objects
communicate, and work together, in a distributed environment (across multiple hosts).
Ofcourse, a DCOM application can work on single host as well.
DCOM objects use the RPC framework. We will see in a minute what that means.
DCOM is just like COM, but in case of DCOM, it uses COM components over several Host computers.
If "COM" sounds a bit alien, then rest assured: many Windows programs are COM components, or use COM components,
like programs as "Wordpad", or the Office Suite (Word, Excel etc..), or parts of SQL Server etc...
The objects usually have implemented "internal functions" (or procedures), which are often called "methods".
You should look at it this way, that a client object, calls a procedure of a Server object in order to get some work done.
This upper statement is already pretty close to what is the "heart" of RPC (Remote Procedure Call).
You might say, that such a implementation resembles a Client/Server setup. It is, but it can be "peer to peer" as well: With DCOM, any component
can be both a provider and a consumer of functionality.
A client object "can talk" to the Server component through method calls. The client could obtain the addresses
of these methods from, for example, a simple table of method addresses (a C++ like "vtable").
This then, is actually one of the possible implementations of "finding methods", by using a compiled "static" approach.
However, the upper statements are not fully correct, when we talk about DCOM. It's pretty close, but in case of DCOM
we must talk about the "Interface descriptions" too.
It's also important to understand that the Operating System find it as one of it's main tasks to "shield" processes (like DCOM processes),
and one process cannot just interfere or talk to another process. That's why a number of "Inter Process Communication" (IPC) techniques
were implemented to achieve just that, like for example "shared memory", "pipes", and "RPC".
Indeed, in DCOM it's the RPC implementation of IPC.
What is very typical of COM/DCOM, is that well-defined Interfaces have to be in place, to access methods of an object.
The objects themselves, appear as if they are black boxes. It is not important how the object was programmed (like using C++ orso).
Only the interface matters: objects cannot be accessed directly, but only through its interfaces.
Questions arise ofcourse, as to how a client "knows" about the available interfaces.
In OO (object oriented) environments, objects and classes are almost the same thing. Generally, a class
is a sort of template from which real objects can be instantiated. In DCOM, people use it the same way, but often
a "class", or "object class", just as easily refers to the live code. Here, we don't care about that too much.
Let's take a look at typical picture (fig. 12) as to how DCOM objects communicate between Hosts:
Fig 12. High-level illustration DCOM communication.
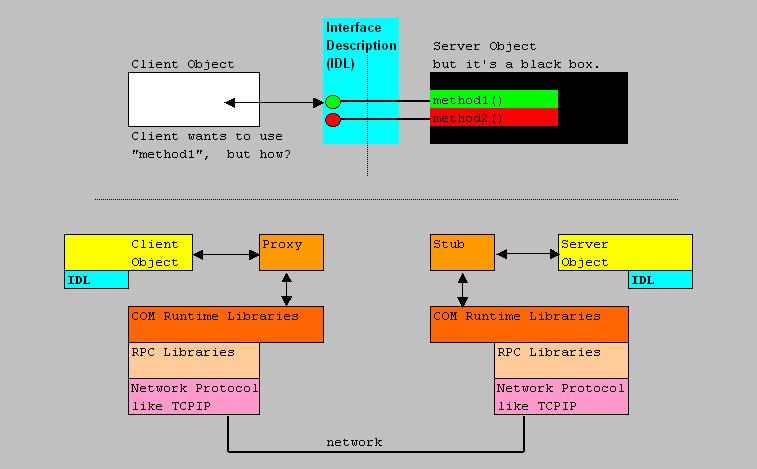
In the figure above, some things really deserve an explanation.
Figure 12 suggest that the client object and server object are on different Hosts. This is called "Remote Server".
So, an "exe" or "dll" client, wants something done by the remote Server object.
The client needs to know about the Interfaces associated with this Server object. The theory is like this:
While setting up a DCOM project, an IDL (Interface Definition Language) file is created that defines the interfaces and its methods,
and also associates these interfaces with an "object class". If such an IDL file is run through an IDL compiler,
then it generates "proxy" and "stub" code and header files which are used by the server code and the client code.
Now, this proxy and stub code will function as an "in process" Server at the client, and an "in process" client at the Server.
It probably sounds strange, but this is how "remoting" is done. As it has turned out, a pure RPC implementation does not work,
and a process of marshalling/unmarshalling "wraps" requests and responses over the RPC network.
So, for example, at the Server object, the stub unwraps a request, and now looks like a local client, which does a method call.
In other words: The proxy resides in the same process as the client. From perspective of the client all interface calls look local.
The proxy takes the client's call and forwards it to where the real Server object is running.
This implementation enables the client to access objects in a different process space, even on a different Host,
as if it's all local in it's own process space. This is often denoted as marshaling.
However, since COM objects are binary objects, and may reside on different platform (NT, OpenVMS, Linux), marshalling
is also used for the representation and serialization of arguments and results, so that it can be correctly understood
by the libraries on those different platforms.
The proxy and stub are COM objects too. The will be created as neccessary.
Next to IDL files, in many cases, like with Visual Basic, socalled type library files (.TBL files) might be created (depending on the environment)
which are binary files, also used to define interfaces and other metadata for COM objects, just like IDL does.
It so can also happen that IDL files get's compiled by the MIDL compiler into a type library (TLB). These sort of files are pretty
good "readable" by several different other environments, what may result in that the metadata for a COM object, can be
imported into another development environment (like DOT NET).
Although you may have the code on the machines, what about when you have lot's and lot's of COM objects and their interfaces?
How do you distinguish between them?
This situation is solved by using "unique ID's" for each interface, and each object (or, as most say: "object class").
So, in order to identify an interface and object, ID's are used. The best sort of ID, are "GUID" or a Globally Unique Identifiers".
These are 16 byte strings, or what is the same, 128 bit strings in hexadecimal, enclosed by curly braces.
- A CLSID is a globally unique identifier that identifies a COM class object.
The "HKEY_LOCAL_MACHINE\SOFTWARE\Classes\CLSID" key stores the CLSID, or it is stored in a deeper level like
"HKEY_LOCAL_MACHINE\SOFTWARE\Classes\identifier\CLSID
- An interface is registered as a IID in "HKEY_LOCAL_MACHINE\SOFTWARE\Classes\Interface".
- DCOM objects hosted by the same executable are grouped into one AppID.
The "HKEY_LOCAL_MACHINE\SOFTWARE\Classes\AppId\AppId" key registers GUID for the AppId.
The above is not a strict listing for all Windows versions.
A Windows system using COM and DCOM, can have lots of registry keys, all identfying Objects and interfaces,
and additional properties like the "thread model" used.
The original DCOM implementations, rely very heavily on the Registry settings.
A later variant, uses a sort of "manifest", like DOT NET does, but stored as a seperate XML file to the executable.
However, since DOT NET was Microsoft's successor to DCOM, DCOM was more or less expected to be phased out
in favor of DOT NET. DOT NET got big indeed, but DCOM did not exactly phased out.
Nowadays it seems that DCOM still holds a "niche" in Business Apllications, and even today it's not a small "niche".
Many large applications use DCOM in various parts, like some components of "SAP", and too many others to list here.
7.1.2 Remote Activation:
It's very important to realize that a DCOM cient can "instantiate" a Server object if that one does not exists yet.
It means that on some Server, probably some .dll is installed, which actually carries the Server object code.
So, suppose we have a SERVER1 with a live client object, which wants to have work done by the DCOM object "SrvObj" on SERVER2.
As a very simple example, take a look at this metacode at SERVER1, which we assume that it gets executed right now.
At SERVER1:
CoInitialize;
COSERVERINFO ServerInfo = {L"SERVER2"};
CoCreateInstanceEx(CLSID SrvObj);
Although it's only a sort of meta code, the "CoCreateInstanceEx(CLSID SrvObj)" statement really is the key to the activation.
Here a remarkable security event takes place. Under which identity may the "SrvObj" object be launched, and
from which places, and at which places? This is for section 7.2.
Note that the CLSID identifies the object class at SERVER2.
7.1.3 A few words on COM:
Since we already have touched on DCOM, which is "COM over the wire", we will only briefly touch on COM.
COM is local, and uses the same notion of "objects", "interfaces" and Registry keys as "CLSID's", in the same way as DCOM does.
Some people distinguish between 3 types of COM, with attention on how COM objects communicate:
- In-process (on the same machine, same process space, No IPC neccessary, the client makes "direct calls")
- Out-of-process (on the same machine, different process spaces, using IPC)
- Remote Server (this is DCOM: objects on different machines, different process spaces, using IPC)
Fig 13. High-level illustration COM communication.
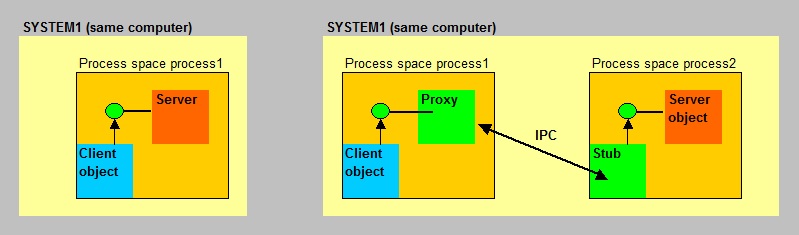
In figure 13, I have left out the "COM runtime libraries" and "RPC libraries" (if they apply), as compared to figure 12.
- For "In-process" COM objects, the client instantiates a Server object which loads in the same process space.
Everything is local to the client and Server objects, and a proxy and stub is not neccessary, since IPC does not apply here.
For example, a dll is loaded and now running in the same process space as the client.
- For "Out-of-process" COM objects, the client instantiates a Server object in a different process space.
IPC is neccessary here, since two processes must communicate. So, a proxy and stub is neccessary, like in DCOM.
Remember from section 7.1.1 why a proxy and stub was neccessary when using IPC (here RPC) ?
But it all happens in the same Operating System, on the same machines.
- Remote Server: already seen in section 7.1.1. See figure 12.
For example, objects on an Application Server connecting to objects on Machine acting as a Service Bus (ESB) etc..
Note: Using IPC as RPC on the local machine, is sometimes called "Local Procedure Call" (LPC).
7.1.4 Does my system use COM or DCOM?
You bet it does. Many components of Microsoft standard programs, and components in suites like Office, are either COM based,
or can call Server objects directly, or use COM/OLE API's to instantiate objects.
Also Business environments, components in Exchange, SQL Server etc.. are based on COM, and sometimes they use "COM across the wire" (DCOM).
Again, if browing the Registry for example, you will find many well-known programs, with references to COM.
7.1.5 A few other facts of DCOM:
⇒ Since it's based on RPC, we know from section 5 that the main port is port 135.
This port is used by the RPC endpoint mapper in Windows, and which is practically mandatory to have open in an internal network.
As we know, the mapper will assign higer ports to applications, but the listener sits on 135.
For this reason, and others, DCOM is certainly "not done" on public interfaces (see section 5 for further explanation).
⇒ DCOM is quite old (early nineties), and was implemented at many locations, before the "Internet Explosion".
The internet apps are often HTML/XML/SOAP (and related tech) based, and that's not the DCOM style.
Web services and newer Microsoft Technologies are ready for Internet apps, but DCOM is not.
⇒ Many cients can be connected to many Server objects. When an object is not referenced anymore, for some time,
it must be removed from memory. When a Server object receives a first request from a new client, a reference counter
in the Server object is increased by one. If communications stop, objects still ping each other at some interval. If a ping is not
received again within 6 minutes, the client is considered to be disconnected, and the reference count decreases by one.
If the reference count reached zero, the Server object will be cleared from memory.
This mechanism actually is the "Garbage Collection" protocol in DCOM.
⇒ Errors related to DCOM can also be found in the "event viewer" of Windows. Possibly, the term "DCOM" is explicitly visible,
or you may see "RPC_some_error" code records too. Sometimes, you may see a CLSID of an object class, or an Appid (see above).
If the information in the eventvwr is not sufficient, you can search the registry on the (for example) the CLSID which is
that 128 bit string between the "{ }".
You can also use the "dcomcnfg" command on 32/64 bit systems, or "C:\WINDOWS\sysWOW64>mmc comexp.msc /32" command
for a 32 bit app on a 64 bit platform.
The registry and the dcom configuration commands, will probably give you pointers to which application it is all about.
Note: always be extra carefull when using those commands on any system of any importance.
7.1.6 rpcdump and Endpoint Mapper:
RPC is a higer level protocol, and usually uses the "winsock/tcpip" stack to access the network. Maybe you want to view figure 6 again in section 5.
How DCOM applications use the RPC protocol, and lower services, can for example be seen in the Registry in:
"HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Rpc".
Here you may find a record like "DCOM protocol: ncacn_ip_tcp", meaning that RPC uses the regular tcpip stack.
Actually, as we have seen in a former section, the "Endpoint Mapper" (RPCSS) usually listens on port 135, and will use higher numbered dynamic ports
to establish communication between RPC servers and clients.
(The term "ncacn" is short for "Network Computing Architecture Connection-Oriented RPC Protocol").
The standard DCOM implementation is not a success for Internet applications, since port 135 must be opened in firewalls,
which nobody will do.
To make DCOM more appealing for Internet applications, the "ncacn_http" protocol was developed, which makes it possibel
to "tunnel" DCOM traffic through a Webserver on both sides.
The WebServers then acts like a "proxy" for DCOM applications.
In fact, "ncacn_http" enables "RPC over HPPT", making it wider in scope than DCOM alone.
Using it with http is "not done". Using SSL, so in fact using HTTPS (HTTP with SSL) could make it acceptable.
Since there exists interoperability issues among versions, be very carefull to make it work with SSL only.
This is a seperate "study" actually, and it probably needs quite some time and effort: Its a bit of an "expert" work only.
rpcdump:
The following protocols can be used by the RPC endpoint mapper:
Local RPC: ncalrpc
TCP/IP: ncacn_ip_tcp
SPX: ncacn_spx
Named pipes: ncacn_np
NetBIOS: netbios
RPC over http: ncacn_http
The rpcdump "endpoint diagnostic utility" (Resource Kit commandline utility) can show you which protocol bindings are registered on your machine.
Using a cmd window (started with "Run As Administrator), you can try:
C:\> rpcdump /I
shows you all...
C:\>rpcdump /p ncacn_http
Querying Endpoint Mapper Database...
0 registered endpoints found.
7.2 A note on Unregistered legacy COM objects:
Please be aware that we are talking about legacy COM or DCOM here. So, like the stuff created with environments like C++,
or VB, before DOT NET was getting a firm hold in development.
So, the discussion below must be viewed in that (somewhat older) context.
You know that for example a "CLSID" identifies a COM object (or "class"). So, tools like "dcomcnfg", or "mmc comexp.msc /32", or regedit,
or tools that goes with a dev environment, will show you the registered COM objects.
With "legacy" COM, objects and interfaces are supposed to be registered in the Registry.
As a side advantage, some tools from development environments like COM/OLE viewer "like" tools, can show you listings of interfaces
and all sorts of metadata. This then suggests, that you get a view on "all" objects.
Immediately, a question arise. Are there "unregistered" COM objects around on your system, and can they still be activated?
And, is that "bad" or not?
I am afraid generally quite a few "unregistered" COM objects are on most systems.
Can such objects be activated? Yes, various ways. For example smart tools can create XML files (or similar files) containing the same information
as would be registered, and in effect creating a manifest for the object. It could make them runnable.
The method above, seems to have some resemblance with DOT NET. Just use a manifest to make something selfdescribing, not using
a repository like the registry.
The opinions with respect to COM vary. "Registration-free COM" is seen as great by many, while others don't that idea at all.
It might be a problem if "Non Admin" people or processes can "just" use COM objects from e.g. powershell, or any other interface,
without the Admin sees (or knows) about any of the objects from the tools listed above.
Or, if you think the above is nonsense: what if people or processes can use unregistered objects, while never before someone with Admin rights,
registered that object (probably using some setup or installer of an application) . In such a context, it was probably never meant
that the object was ever to be used.
It might even be considered to be a way in which a non-Admin might "outsmart" an Administrator.
If you say that's "bs", then maybe you are right. I think it's not. Maybe it's just a bit of a fuzzy area.
Anyway, "Registration-free COM" was even supported by Microsoft, and several MSDN articles describe the way to implement it.
Seen from that angle: how bad can it be then?
There is no "good" or "bad" here. Legacy COM just makes it all possible. And, suppose you were not aware of it, then now you are, and that's probably good.
7.3 Configuring DCOM in Win7 / Win2K8 (R2) systems:
! Warning !:
Maybe it looks a bit exaggerated, but I don't want to be the guy who gave the wrong advise.
So, I better start with a warning here! Better not use the information presented here, as the sole basis for removing accounts.
For example, removing too much might cripple your system, or cripple applications.
It's very important to get more information, and perform a test first. The material in this note may serve as "just one" of your sources
This is so, since the discussion below also refer to "Everyone" and "Anonymous Logon" usage in COM/DCOM.
All text in this section applies to test scenario's only.
The following figures shows you typical COM/DCOM "security setting" dialog boxes in (Win7) Win2K8/Win2K8R2 systems.
Those systems are still very prominent Operating Systems, in business environments.
So, it's very wise to check your System-wide, and application specific, security settings.
Some short comments, and recommendations, will accompany figures 14-18 shown below.
The dialog boxes can be seen (Win7/Win2K8) by starting the "dcomcnfg" utility from the command prompt.
They look "harmless" but they may have a large impact on system security.
Important:
Using GPO (or policies) on the AD level is much more effective, than a "per Server approach" as seen below.
However, I just want to show and comment on the COM/DCOM dialogboxes, since that might be helpfull for understanding the procedure.
Fig. 14. Enabling/Disabling DCOM at the System level.
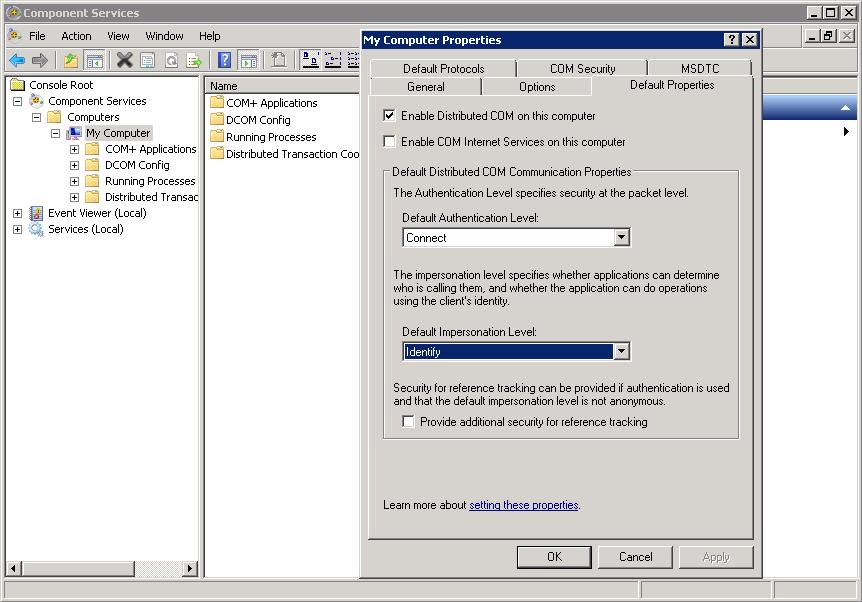
See fig. 14. Note that I have rightclicked the My Computer object, and choose "properties".
All controls here, are very important. These are system-wide settings.
⇒ Enable/Disable DCOM:
If your system uses DCOM, then enable it, if the system is purely on an internal network.
What DCOM is, was touched upon in section 7.1, so at least you should have a basic idea on what it is.
Note that many insist on disabeling DCOM. However, depending on the functions of your Server, some features might not work anymore,
like e.g. Replication of databases, "connectors" between applications, and many more examples are possible.
In general, a consensus seems to exist to disable it for high security requirements.
Recommendation: No recommendation is possible. Just depends on the situation.
⇒ Enable/Disable COM Internet Services:
For COM/COM+ services over the Internet, no requirements should exists for internal Servers. The "default" is off, and you should never enable this one.
If a consultant, or developer or so, advises to put in it back on, he/she should provide for a 100% valid explanation for that action.
If not 100% convinced, or if you still can't interpret the explanation, keep it "OFF" at all times.
"ON" would also activate the "tunneling" protocol as was touched in section 7.1.6. Using SSL makes it better, but it's also hard to configure such setup so that it is secure.
Recommendation: keep it "OFF".
⇒ Default Athentication Level:
This one is not easy. It's about "authentication" on the packet level. It means: are the packets originating from the client you expect it to be?
To achieve it, a number of options can be select. See the list below.
But..., what if a programmer has used an "override" for this setup? Then your "default" is gone.
However, choosing the most stringent option here is certainly advised. Ofcourse, some apps might then not work anymore.
- Default: The authentication level is chosen as to be the regular COM(+) negotiation algorithm.
- None: No authentication. Do not implement this.
- Connect: Authenticates the client only when the client first connects to the server.
- Call: Authenticates the client at each remote call.
- Packet: Authenticates client, and verifies that all data received is from this client.
- Packet Integrity: Authenticates client, verifies that all data received is from this client, and not modified.
- Packet Privacy: As above, and encryption on.
Recommendation for Testing: Choose the best level, that is: 7 or 6 or 5. Never choose 2.
Please note the word "Testing" in the above recommendation.
⇒ Default Impersonation Level:
"Impersonation" means that the Server (who gets request from the client), acts "as if" it is the client when
accessing resources. But these "resources", are they local to the Server object, or remote? That makes a difference as well.
See the following list for the options to choose from.
- Default: The impersonation level is chosen as to be the regular COM(+) negotiation algorithm.
- Anonymous: The client is anonymous. The Server object will not act "as if" it is the client, but as itself.
- Identify: The server gets the client's identity. The server object uses it for ACL checking, but it cannot access resources as if it is the client.
- Impersonate: The server gets the client's identity. It uses the client's token to access resources local to the Server's machine.
- Delegate: The server gets the client's identity. It uses the client's token to access resources local to the Server's machine, and remote resources.
Recommendation: I think no general recommendation is possible here. It just depends on the situation.
Let's go to the next dialogbox.
Fig. 15. Access and Activation permissions at the System level.
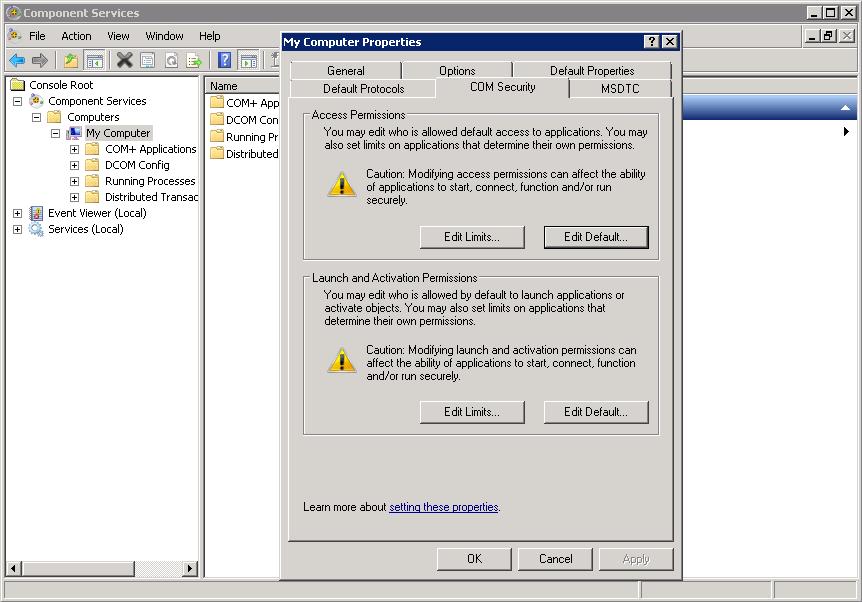
See fig. 15. Note that I am still busy browsing the properties of the My Computer object.
So, again these concern system-wide settings, and not on a particular COM component (which can be done too).
Note too that this tab is about COM security, meaning "activation", "access" and "launch" permissions granted to users and/or groups.
It means too, that we are talking about COM objects on "this" machine.
In listings of users and groups, you can evidently remove and add users/groups.
However, it can be a bit dangerous to remove accounts which turned out to be essential. So, all text only applies for test scenarios's.
Since figure 15 is about global settings, an override is possible on setting permissions on the individual COM component level.
Actually you should have a good idea on "who" may launch any COM object, since this is a systemwide setting.
As of Win2K3 SP1, the "Distributed COM users" group is available, and this Windows group is a good choice to use
in permission lists for authenticated users. As always, you can add user accounts and Domain Groups in this special group.
Fig. 16. The "Distributed COM users" as a Local Group in Windows Servers.
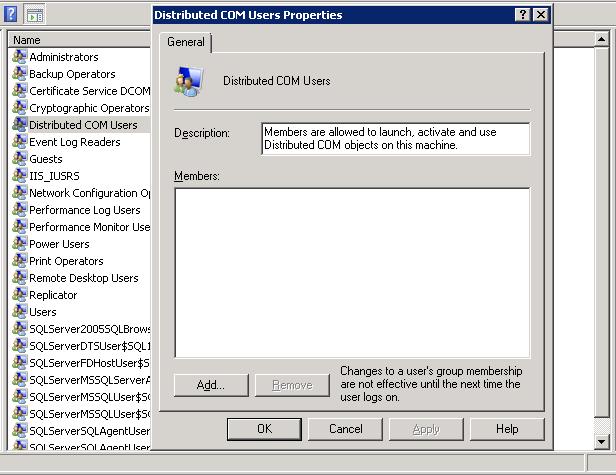
=> If you see "Everyone" in listings, it looks better (safer) to remove that group.
But there could be a "catch" here if you remove it.
=> Secondly, you might even find the "Anonymous Logon" ('NT AUTHORITY\ANONYMOUS LOGON') listed.
But there could also be a very LARGE "catch" too if you remove it.
The "Everyone" group covers almost all connections (so to speak). The "Anonymous Logon" is not a member of Everyone.
The "ANONYMOUS LOGON" is sometimes a better option than Everyone. It sounds "spooky", but it's often
neccessary. Ofcourse, ideally, you would work with fully authenticated users only.
A problem might arise if programmatic objects, or services, uses the "Anonymous Logon". And they often do.
So, killing this one, is not a simple task.
A COM client application might be able launch a remote COM Server, but is unable to receive further responses
if the "anonymous logon" is removed from permission lists. Thus, the Client will be unable to continue communicating
with the Server application.
Note:
You could even use the "Anonymous Logon" in almost all ACL's, as of for example NTFS, and even in COM.
Recommendations for Testing:
1. For normal accounts, consider using "Distributed COM users".
2. You might try removing "Everyone" in a test environment, but chances are that apps do not work anymore.
Please note the word "test" in the above recommendations.
Catches:
1. The "System" account is member of "Everyone" too. Implicitly, COM classes might be activated using the System account.
But you can add System seperately in permission listings.
2. The "Anonymous Logon" is used for COM messaging. This could pose a problem too, if you remove it.
You need more information before touching this one.
Although certainly not satisfactory, I hope that this section was usefull anyway.
Section 8. Some notes on .NET / WinRT Security
Section 9. A short study on the Win Architecture, and a few well known exploits on Windows