A microscopic small note on Netapp.
Version : 0.1
Date : 25/12/2012
By : Albert van der Sel
1. A Microscopic small note on Netapp.
1.1 A quick overview.
NetApp is the name of a company, delivering a range of small to large popular SAN solutions.
It's not really possible to "capture" the solution in just a few pages. People go to trainings for a good reason:
the product is very wide, and technically complex. To implement an optimal configured SAN, is a real challenge.
So, this note does not even scratch the surface, I am afraid. However, to get a high-level impression, it should be OK.
Essentially, a high-level description of "NetApp" is like this:
- A controller, called the "Filer" or "FAS" (NetApp Fabric-Attached Storage), functions as the managing device for the SAN.
- The Filer runs the "Ontap" Operating System, a unix-like system, which has it's root in FreeBSD.
- The Filer manages "diskarrys" which are also called "shelves".
- It uses a "unified" architecture, that is, from small to large SANs, it's the same Ontap software, with the
same CL and tools, and methodology.
- Many features in NetApp/Ontap must be seperately licensed, and the list of features is very impressive.
- There is a range of SNAP* methodologies which allows for very fast backups, and replication of Storage data to other another controller and its shelves,
and much more other stuff, not mentioned here. But we will discuss Snapshot backup Technology in section 1.4.
- The storage itself uses the WAFL filesystem, which is more than just a "filesystem". It was probably inspired by "FFS/Episode/LFS",
resulting in "a sort of" Filesystem with "very" extended LVM capabilities.
Fig. 1. SAN: Very simplified view on connection of the NetApp Filer (controller) to diskshelves.
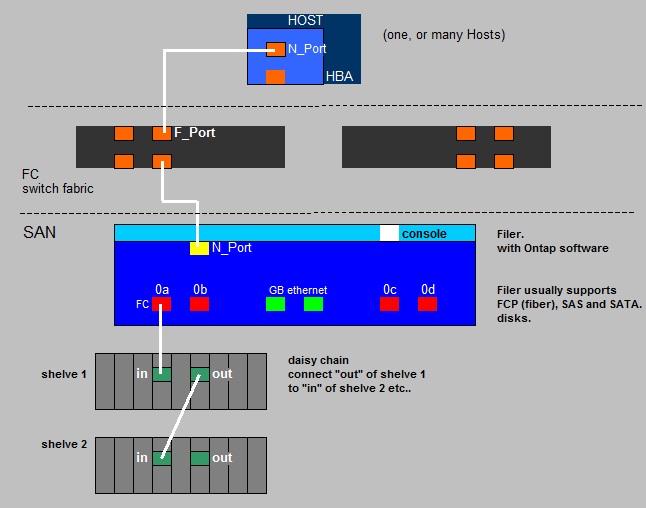
In the "sketch" above, we see a simplified model of a NetApp SAN.
Here, the socalled "Filer", or the "controller" (or "FAS"), is connected to two disk shelves (disk arrays).
Most SANs, like NetApp, supports FCP disks, SAS disks, and (slower) SATA disks.
Since quite some time, NetApp favoures to put SAS disks in their shelves.
If the Storage Admin wants, he or she can configure the system to act as a SAN and/or as a NAS, so that it can provide storage using either
file-based or block-based protocols.
The picture above is extremely simple. Often, two Filers are arrangend in a clustered solution, with multiple paths
to multiple diskshelves. This would then be a HA solution using a "Failover" technology.
So, suppose "netapp1" and "netapp2" are two Filers, each controlling their own shelves. Then if netapp1 would fail for some reason,
the ownership of its shelves would go to the netapp2 filer.
1.2 A conceptual view on NetApp Storage.
Note from figure 1, that if a shelve is on port "0a", the Ontap software identifies individual disks by the portnumber and the disk's SCSI ID,
like for example "0a.10", "0a.11", "0a.12" etc..
This sort of identifiers are used in many Ontap prompt (CL) commands.
But first it's very important to get a notion on how NetApp organizes it's storage. Here we will show a very high-level
conceptual model.
Fig. 2. NetApp's organization of Storage.
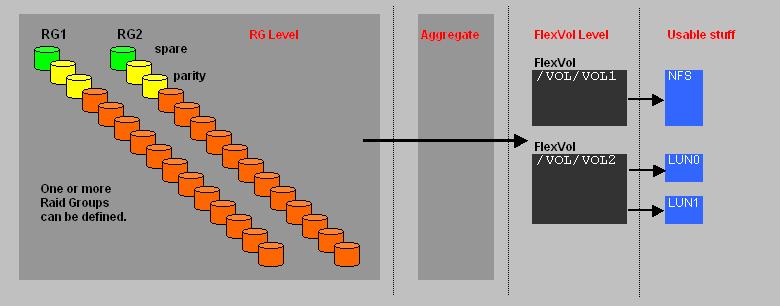
The most fundamental level is the "Raid Group" (RG). NetApp uses "RAID4", or "RAID6 with double parity (DP)" on two disks,
which is the most robust option ofcourse. It's possible to have one or more Raid Groups.
An "Aggregate" is a logical entity, composed of one or more Raid Groups.
Once created, it fundamentally represents the storage unit.
If you want, you might say that an aggregate "sort of" virtualizes the real physical implementation of RG's
Ontap will create RG groups for you "behind the scene" when you create an aggregate. It uses certain rules for this,
depending on disk type, disk capacities and the number of disks choosen for the aggregate. So, you could end up with one or more RG's
when creating a certain aggregate.
As an example, for a certain default setup:
- if you would create a 16 disk aggregate, you would end up with one RG.
- if you would create a 32 disk aggregate, you would end up with two RG's.
It's quite an art to get the arithmetic right. How large do you create an aggregate initially? What happens if additional spindles
become available later? Can you then still expand the aggregate? What is the ratio of usable space compared to what gets reserved?
You see? When architecting these structures, you need a lot of detailed knowledge and do a large amount of planning.
A FlexVol is next level of storage, "carved out" from the aggregate. The FlexVol forms the basis for "real" usable stuff, like
LUNs (for FC or iSCSI), or CIFS/NFS shares.
From a FlexVol, CIFS/NFS shares or LUNs are created.
A LUN is a logical representation of storage. As we have seen before, it "just looks" like a hard disk to the client.
From a NetApp perspective, it looks like a file inside a volume.
The true physical implementation of a LUN on the aggregate, is that it is a "stripe" over N physical disks in RAID DP.
Why would you choose CIFS/NFS or (FC/iSCSI) LUNs? Depends on the application. If you need a large share, then the answer is obvious.
Also, some Hosts really need storage that acts like a local disk, and where SCSI reservations can be placed on (as in clustering).
In this case, you obviously need to create a LUN.
Since, using NetApp tools, LUNs are sometimes represented (or showed) as "files", the entity "qtree" gets meaning too.
It's analogous to a folder/subdirectory. So, it's possible to "associate" LUNs with a qtree.
Since it have the properties that a folder has too, you can associate NTFS or Unix-like permissions to all
objects associated to that qtree.
1.3 A note on tools.
There are a few very important GUI or Webbased tools for a Storage Admin, for configuring and monitoring their Filers and Storage.
Once "FilerView" (depreciated on Ontap 8) was great, and followup versions like "OnCommand System Manager" are probably indispensable too.
These type of GUI tools allow for monitoring, and creating/modifying all entities as discussed in section 1.2.
It's also possible to setup a "ssh" session through a network to the Filer, and it also has a serial "console" port for direct communication.
There is a very strong "command line" (CL) available too, which has a respectable "learning curve".
Even if you have a very strong background in IT, nothing in handling a SAN of a specific Vendor is "easy".
Since, if a SAN is in full production, almost all vital data of your Organization is centered on the SAN, you cannot afford any mistakes.
To be carefull and not taking any risks, is a good quality.
There are hundreds of commands. Some are "pure" unix shell-like, like "df" and many others. But most are specific to Ontap like "aggr create"
and many others to create and modify the entities as discussed in section 1.2.
If you want to be "impressed", here are some links to "Ontap CL" references:
Ontap 7.x mode CL Reference
Ontap 8.x mode CL Reference
1.4 A note on SNAPSHOT Backup Technology.
One attractive feature of NetApps storage, is the range of SNAP technologies, like the usage of SNAPSHOT backups.
You can't talk about NetApp, and not dealing with this one.
From Raid Groups, an aggregate is created. From an aggregate, FlexVols are created. From a FlexVol, a NAS (share) might be created,
or LUNs might be created (accesible via FCP/iSCSI).
Now, we know that NetApp uses the WAFL "filesystem", and it has its own "overhead", which will diminish your total usable space.
This overhead is estimated to be about 10% per disk (not reclaimable). It's partly used for WAFL metadata.
Apart from "overhead", several additional "reservations"are in effect.
When an aggregate is created, per default "reserved space" is defined to hold optional future "snapshot" copies.
The Storage Admin has a certain degree of freedom of the size of this reserved space, but in general it is advised
not to set it too low. As a guideline (and default), often a value of 5% is "postulated".
Next, it's possible to create a "snapshot reserve" for a FlexVol too.
Here the Storage Admin has a certain degree of freedom as well. NetApp generally seems to indicate that a snapshot
reserve of 20% should be applied. However, numbers seem to vary somewhat when reading various recommendations.
However, there is a big difference in NAS and SAN LUN based Volumes.
Here is an example of manipulating the reserved space on the volume level, setting it to 15%, using the Ontap CL:
FAS1> snap reserve vol10 15
Snapshot Technologies:
There are few different "Snapshot" technologies around.
One popular implementation uses the "Copy On Write" technology, which is fully block based or page based. NetApp does not use that.
In fact, NetApp uses "a new block write", on any change, and then sort of cleverly "remebers" inode pointers.
To understand this, lets review "Copy On Write" first, and then return to NetApp Snapshots.
⇒ "Copy On Write" Snapshot:
Fig. 3. "Copy on Write" Snapshot (not used by NetApp).

Let's say we have a NAS volume, where a number of diskblocks are involved. "Copy on Write" is really easy to understand.
Just before any block gets modified, the original block gets copied to a reserved space area.
You see? Only the "deltas", as of a certain t=t0 (when the snapshot was activated), of a Volume (or file, or whatever)
gets copied. This is great, but it involves multple "writes": first, write the original block to a save place, then write the
the block with the new data.
In effect, you have a backup of the entity (the Volume, the file, the "whatever") as it was at t=t0.
If, later on, at t=t1, you need to restore, or go back to t=t0, you need the primary block space, and copy the all reserved
(saved) blocks "over" the modified blocks.
Note that the reserved space does NOT contain a full backup. It's only a collection of blocks freezed at t=t0, before they
were modified between t=t1 - t=t0.
Normally, the reserved space will contain much less blocks than the primary (usable, writable) space, which means a lot of saving
of diskspace compared to a traditional "full" copy of blocks.
⇒ "NetApp" Snapshot copy: general description (1)
You can schedule a Snapshot backup of a Volume, or you can make one interactively using an Ontap command or GUI tool.
So, a Netapp Snapshot backup is not an "ongoing process". You start it (or it is scheduled), then it runs until it is done.
The mechanics of a snapshot backup are pretty "unusual", but it sure is fast.
Fig. 4. NetApp Snapshot copy.
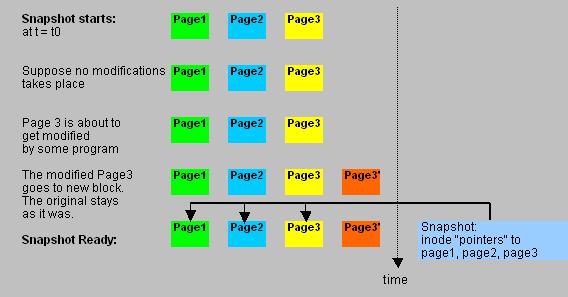
It's better to speak of a "Snapshot copy", than of a "Snapshot backup", but most of us do not care too much about that.
It's an exact state of the Volume as it was at t=t0, when it started.
With a snapshot running, WAFL takes a completely another approach than many of us are used to. If an existing "block" (that already contained data),
is going to be modified while the backup runs, WAFL just takes a new free block, and puts the modified block there.
The original block stays the same, and the inode (pointer) to that block is part of the Snapshot !
So, there is only one write (that to the new block). The inode (a pointer) of the original block is part of the Snapshot.
It explains why snapshots are so incredably fast.
⇒ "NetApp" Snapshot copy: the open file problem (2)
From Ontap's perspective, there is no problem at all. However, many programs run on Hosts (Servers) and not on the Filer ofcourse.
So, applications like Oracle, SQL Server etc.. have a completely different perspective.
The Snapshot copy might thus be inconsistent. This is not caused by Netapp. Netapp only produced a state image of pointers at t=t0.
And that is actually a good backup.
The potential problem is this: NetApp created the snapshot at t0, during the t0 to t=t1 interval.
In that interval, a database file is fractioned, meaning that processes might have updated records in the databasefiles.
Typical of databases is, is that their own checkpoint system process flushes dirty blocks to disk, and update
fileheaders accordingly with a new "sequence number". If all files are in sync, the database engine considers the database
as "consistent". If that's not done, the database is "inconsistent" (so the database engine thinks).
By the way, it's not databases alone that behave in that manner. Also all sorts of workflow, messaging, queuing programs etc..
show similar behaviour.
Although the Snapshot copy is, from a filesystem view, perfectly consistent, Server programs might think differently.
That thus poses a problem.
Netapp fixed that, by letting you install additional programs on any sort of Database Server.
These are "SnapDrive" and "SnapManager for xyz" (like SnapManager for SQL Server).
In effect, just before the Snapshot starts, the SnapManager asks the Database to checkpoint and to "shut up" for a short while (freeze as it were).
SnapDrive will do the same for any other open filesystem processes.
The result is good consistent backups at all times.