An attempt to say something useful on SQL Server 2012 AlwaysOn cluster implementations.
Version :0.7
Date : 07/09/2014
By : Albert van der Sel
Type : A very simple note on "SQL Server 2012 AlwaysOn" . It's probably only usable for starters.
CONTENTS:
1. Introduction, and comparing "Standard Failover clustering" with "AlwaysOn Failover clustering".
2. Quorum models in Windows Clustering.
3. active/passive and active/active Clustering.
4. Setting up an AlwaysOn Failover Cluster and Availability Groups.
5. A few words on managing AlwaysOn using TSQL (including Failover).
Appendices:
1. Systemviews on AlwaysOn.
2. Windows Failover Cluster troubleshooting.
There exists several types of "clusters", like for example a "computing cluster", where for example, say,
20 Nodes or so (independent computers), are simultaneously working on a complex model from physics, or mathematics.
Here, the importance lies on cumulative computing force.
In other types of clusters, "High Availability" (HA) is the main issue. Business Applications then, are configured
to be available all the time, even if one (or more) node(s) crashes.
A special class of HA, form the "Failover Cluster" implementations. Now, the "AlwaysOn" HA implementation on SQL Server
is the main theme of this simple note. But, I think, that it is very important to know the differences and similarities of "two" important
SQL Server "HA" cluster implementations: AlwaysOn- and the Traditional SQL Cluster.
As an example of a "Failover Cluster", consider this simple case. Suppose you have two Nodes (computers). Only one of those two
servers the users. If that particular node "fails", then the other one takes over.
Indeed, one node was "idle" (or passive) all the time, until the moment that the active node fails.
This "two-node" example can be extended with an additional node. In a three-node cluster, the chance that two nodes fail is very, very small.
But, only one is actually "active", while two others are "passive", and only have a stand-by role.
At least, the above statement is true for "traditional Windows failover clusters". It must be said that on the SQL level, using
AlwaysOn, the situation has an "additional" dimension.
This note will discuss the similarities and differences between AlwaysOn, and the more traditional failover clustering option.
If we view 'SQL Server' is a business application, which must be made High Available, then two main options exists:
- (1): the SQL Server standard Failover cluster, and
- (2): the SQL Server AlwaysOn Failover cluster.
The classification "failover" already says it all: If one Node fails, another Node will take over (or resume) the resources,
and provide access to SQL Server.
I will start this note by comparing those two Cluster implementations.
1. Introduction, and comparing Standard Failover clustering with AlwaysOn failover clustering.
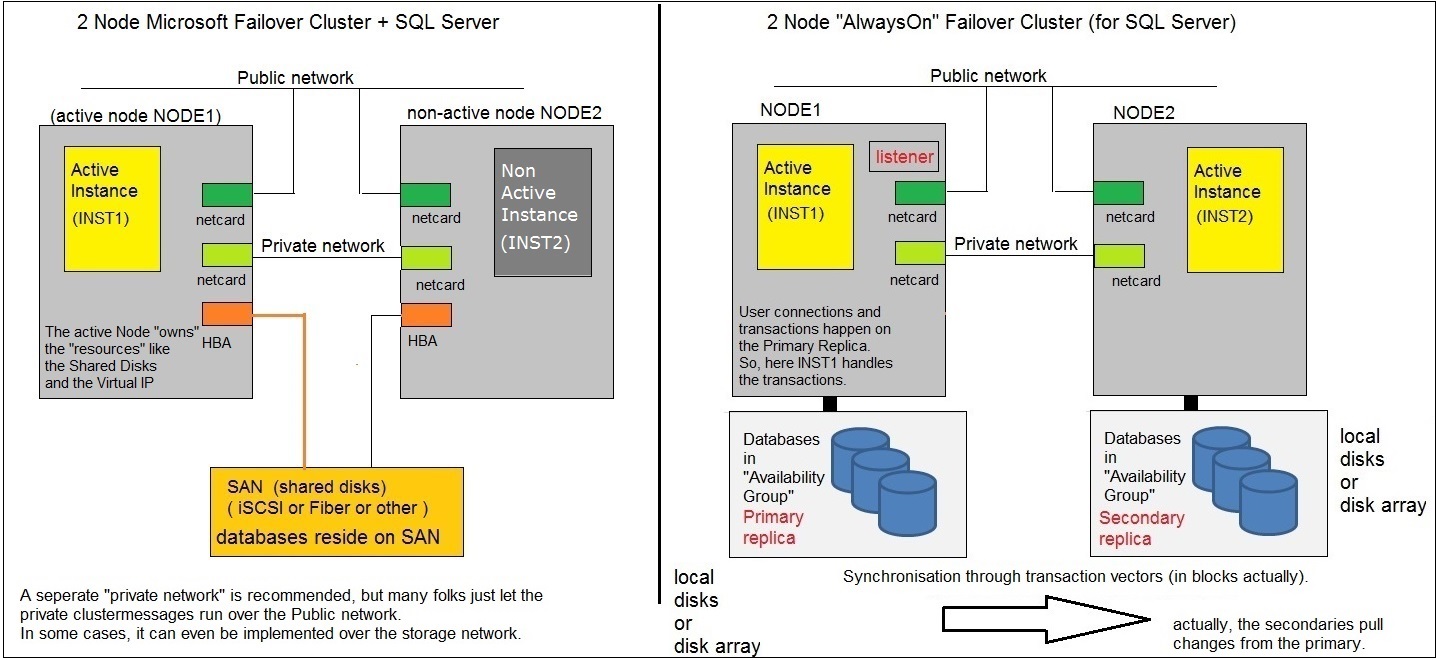
The figure below, tries to picture some main features of both types of clusters. However, here we see two-Node systems.
Although some "restrictions" exists, you might create a 3 Node Cluster, or a 4 Node (etc..) cluster as well.
Later on, we will see more on some of those "restrictions" (related to the number of nodes).
Fig 1.
=> Here are some "striking" similarities with respect to both types:
Both use (and are dependent on) the "Windows Failover feature". This is a stacked layer of OS software components
(from HA drivers to dll implementations), which can deal with shared components, monitor the cluster, and can react
on cluster events (like a Node failure which might trigger a Failover).
Both use a "private" heartbeat Network, between the nodes, which is primarily used to monitor the state and "health" of the Nodes.
Quite often, the private network is simply omitted, and the public network is used for clustermessages too. It's not recommended,
but people just do that to avoid extra costs (or for other reasons).
Both use a "public" network, which provide the user community access to the Clustered service.
Ofcourse, this network is mandatory.
Both use a Cluster database which is a repository of the names and attributes of Cluster components and shared resources (later much more on this).
This is a cluster centric database, as the physical file "%Systemroot%\Cluster\Clusdb". It is also represented in the registry,
as the hive "HKLM\Cluster". Here you may find stuff like networknames plus attributes, storage, clustername, nodenames etc..
Both use a similar "quorum model" which defines a "tie breaker" or "referee" on issues like which node is the resource "owning" node,
(primary node), and can also handle issues like "which Node gets control" if the current Primary node fails (later much more on this).
Ofcourse all netcards on all nodes, have an IP address configured. But (and this may sound a bit remarkable at first), there are also "Virtual IP's"
in use. In an AlwaysOn Cluster, this is related to the socalled "listener", and in a (normal, regular) standard Cluster there is a "Virtual IP" (VIP)
that "travels" along with the SQL Server service, if a failover event occurs. The listener, or VIP, is implemented so that users always connect
to a fixed IP address, independent on which Node SQL Server provides Database services now.
=> Here are some "striking" differences with respect to both types:
The "SQL Server standard Failover cluster" usually uses LUNs from a SAN, on which the databases reside on. Although the disk
are said to be "shared", ONLY one Node (the active one) is the current"owner" and has exclusive access to those LUNs.
Only at a Failover, another Node obtains ownership, and gets excusive access.
Contrary, the Nodes of the "SQL Server AlwaysOn Failover cluster" uses local disks, or local diskarrays (possibly with some RAID implementation).
The Primary Node has on it's local disks, the Primary Replica of the databases. The secondary Node (or Nodes) has a "Secondary Replica",
which is a copy of the Primary Replica. The databases between Primary and secondary, are "mirrorred", usually using a "synchroneous commit"
implementation. This means that a transaction on the Primary Replica is considered to be complete, only if the secondary (or secondaries)
are updated as well.
In the "SQL Server standard Failover cluster", only one SQL Server Instance is active, on the currently active Node.
When a fault condition arises at the Active Node, the ownership of shared resources (such as the LUNs on a SAN) are "transferred"
to another Node. On that other Node, the SQL Server Instance is started and opens the databases residing on those LUNs.
This is why, in figure 1, on the left side, the SQL Server Instance "INST1" (on Node1) is shown to be Active (up and running),
while the SQL Server Instance "INST2" (on Node2) is shown to be down.
In the "SQL Server AlwaysOn Failover cluster", things are different. On all nodes, a SQL Server Instance is up and running.
Only on the Primary Instance, user connections are established and transactions run. The transactions are replicated to all
"secondary replica's" on all the other Nodes.
If you have carefully read the above similarities and differences, most of the Windows Cluster features are the same,
and the differences are most obvious on the SQL Server level.
It's important to know that:
- with the "SQL Server standard Failover cluster", when a Failover occurs, another SQL Instance
on another Node is started, and gets ownership of all resources.
-- with the "SQL Server AlwaysOn cluster", when a Failover occurs, the role of the Primary and a Secondary replica
are switched. After failover, what once was a Secondary Replica, is now the (leading) Primary Replica.
Another thing is that thus a SAN is not needed if you want to set up an "AlwaysOn Cluster". Usually, just local disks are used.
In this case, the HA sits in the fact that Replica's of the Primary databases exists on the storage of other Nodes as well, and are in sync
with the Primary.
Not using a SAN, often simplifies a Cluster installation somewhat.
And you do not need to use, and configure, Fiber HBA's, or iSCSI netcards
A simple example of Administering an AlwaysOn Cluster:
A taste of management of an AlwaysOn cluster, using TSQL (instead of using the graphical SSMS), will be the subject of Chapter 5.
However, a simple example right now, might be illustrative.
Once the SQL Instances on the Nodes are up and running, creating and further management of Availability Group(s) (=Replica's)
can be done using the graphical "Management Console", or TSQL.
Once created, it's quite easy to manage them (like adding a database to an Availability Group), or
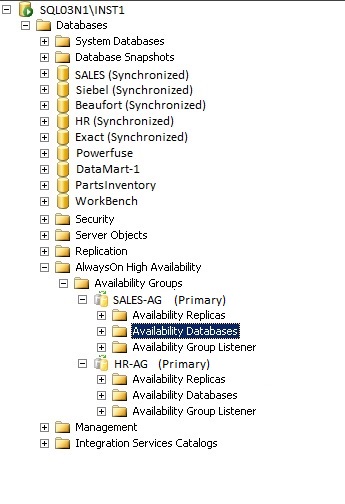
reverse the role between a Primary- and Secondary Replica. Below you see an example of an Instance (SQL03N1\INST1),
where a number of databases are placed in two availability groups.
The databases who are part of an availability group, clearly show the "Synchronized" property behind their name.
Furthermore, take notice of the Availability Group container. If you would click further on such Availability Group (like "sales-ag"),
you would see which databases are member of that particular Availability Group (or Replica).
Also, if you would rightclick "sales-ag", you could add a database to that Availability Group.
Here is an example of using "systemviews". Those views can be helpfull in documenting and monitoring the state and health
of an AlwaysOn Cluster (especially the Replica's).
Again, more on this in Chapter 5.
- Suppose we have the cluster node "SQL03N1", with the SQL Instance "INST1"
Suppose further, that we have the Availability Groups "sales-ag" and "hr-ag". Then both will have their own
associated "listeners" (where each listener uses a unique "VIP").
We can see that easily using the graphical "SQL Server Management Console", or using "systemviews".
Here is an example:
select substring(g.name,1,20) as "AG name" , l.listener_id,
substring(l.dns_name,1,30) as "Listener name", l.port,
substring(l.ip_configuration_string_from_cluster,1,35) AS "VIP"
from sys.availability_groups g, sys.availability_group_listeners l
where g.group_id=l.group_id
AG name....listener_id..................................Listener name............port......VIP
----------------------------------------------------------------------------------------------
sales-ag...bd2507da-adba-4d0d-b893-d6ff5d9a1a6b.........sales-ag-lsnr............1433......('IP Address: 145.20.90.133')
hr-ag......9b0c0909-fedf-4c8a-a65d-f17a5497d116.........hr-ag-lsnr...............1433......('IP Address: 145.20.90.132')
Never forget that an Availability Group (an active one), is at least one Primary Replica and a Secondary Replica (or more Secondaries).
An associated listener makes sure that the VIP "points" to the current Primary Replica (where transactions happen).
Even after a Failover, the listener with it's VIP, points to the Primary which is now the current and leading one.
Notes on Backup/Restore of databases in an Availability Group (Replica).
With respect to database backup and restore procedures, for a "SQL Server standard Failover cluster" it is very much the same
as with a "standallone" SQL installation. Since there is actually only one "live" Instance working on the same set of databases
on SAN storage, you can just backup and restore databases in the usual way.
With an "AlwaysOn Failover Cluster", a restore goes with additional steps. First, you need to "evict" (remove) that particular database
from the "Availability Group". Then perform the Restore on the Primary Instance. Then you use the regular procedure to add
that database back to the "Availability Group". It is not that it's difficult, but it's simply a fact, that there just are
some additional steps.
2. Quorum models in Windows Clustering.
Do not forget, that both the "SQL Server standard Failover cluster", and the "SQL Server AlwaysOn Failover cluster", just
use "Windows Server Failover Cluster" (WSFC) as the basis. So, on the OS level and Cluster level, both SQL Server
Cluster technologies are identical.
Working with Cluster technologies, an idea of the "Quorum" and different "Quorum models" is essential.
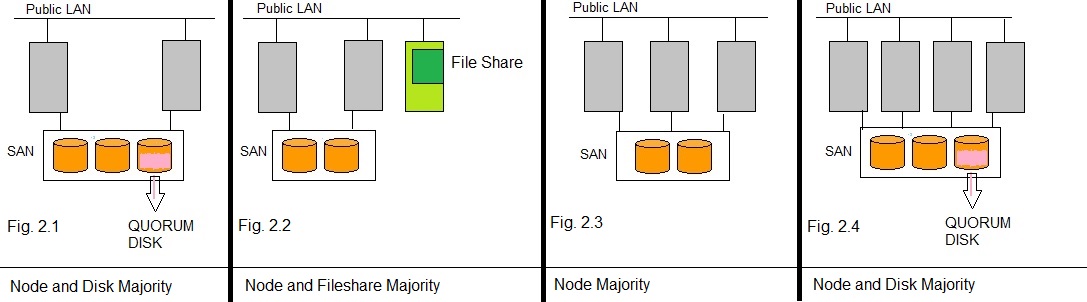
Fig 2.
Quorum is a measure for a "number of votes", to take a decision if "something is still good". This is indeed so for Microsoft Clusters.
Suppose you have a 3 Node Cluster, with Node1 (suppose the Active one), Node2, and Node3.
If Node3 fails, two Nodes remain, and Cluster functionality is still in place. The two remaining Nodes know which one is
the Active one, and which is the passive one. We still have "2/3" of the full voting capacity in place.
Suppose you have a 4 Node cluster with Node1 (suppose the Active one), Node2, Node3, and Node4. Suppose a "communications split"
occurs between the set Node1, Node2 and the second set Node3, Node4.
If we would not have a "quorum model" in place, Node3 and Node4 might think that Node1 and Node2 are dead, and that they should
continue Cluster functionality. However, the same holds for Node1 and Node2.
This would lead to bizarre situations.
If however, in the above example, another vote is present, say a "Quorum Disk" (indeed a disk), then we might have again
a communication split that devides the cluster in the set {Node1,Node2) and the set {Quorum disk,Node3,Node4}.
Since Node3 and Node4 still can "see" the Quorum disk, they know they have "3/5" votes from the total number of possible votes (5).
However, Node1 and Node2 now know they cannot see the Quorum Disk anymore, and their total votes will be "2/5" from the total votes.
This is lower than what what the set {Quorum disk,Node3,Node4} have.
Node1 and Node2 know they are "lost" and the Cluster services will shut down.
It will result in the situation that a "split" cluster is avoided, and bizarre results are not possible anymore.
You can work out many more examples yourself.
It all results in the following:
If you have an even number of true Nodes, and you want to avoid bizarre splits, then either add another Node to get
to an uneven number of Nodes, or add another vote in the form of a (quorum) "Fileshare" (on some non-Cluster machine),
or add a SAN Lun (visible to all nodes), which will act as a quorum Disk (or vote).
So, suppose you have 6 Nodes, and cannot afford a 7th Node, and you want to avoid a bizarre split, then add a FileShare,or
quorum Disk. This will the always result in the fact that, if a communications split occurs,
there will ALWAYS be a set of nodes with a higher number of votes compared to the other set of Nodes.
So, in principle:
Using an even number of Nodes, then you must use an additional Fileshare vote, or a quorum disk (SAN) as a vote.
Using an uneven number of Nodes, then in principle, if a split occurs "somewhere", there will always be a set
with a higher number of votes, so in principle, an additional Fileshare vote, or a quorum disk (SAN) as a vote, is Not Needed.
Please take a look at figure 2. For example, do you understand why the model in fig. 2.4, uses an additional Quorum Disk?
Notes:
- A Quorum diks, is also often called a "Disk witness".
- Similarly, a Fileshare vote is also often called a "Fileshare witness".
The models in Figure 2, all look like a "SQL Server standard Failover cluster", and not like a "SQL Server AlwaysOn Failover cluster"
This is probably suggested by the presence of the SAN. Indeed, an "AlwaysOn Cluster" often uses local Storage at the Nodes.
But that does not change the reasoning of this section at all!. First an "AlwaysOn Cluster" might use a SAN as well, and thus
a Quorum Disk can be created which fuctions as described above. An "AlwaysOn Cluster" might use local Storage for the replica's, and
a Quorum Disk on a SAN.
However, most Admins or DBA's are attracted by the fact that a costly SAN can be avoided, and if they want to use an even Node cluster,
they just simply add a "Fileshare witness".
This ordinary FileShare is just a "share", created by the Cluster setup program (if you choose that model), and it should be
on a non-Cluster Node, but ofcourse it must be "visible" to all Nodes.
3. active/passive and active/active Clustering.
I thought this note was going to be mostly about "AlwaysOn", but in the process, I realized that AlwaysOn Clustering cannot
be fully appreciated or understood if not the essentials of standard SQL clustering is on the menu too.
The notion of Active/passive and active/active Clustering, only really applies to "SQL Server standard Failover clusters".
So what is it, and how does it compare to AlwaysOn Clustering?
3.1 Let's see how it is in AlwaysOn SQL Clustering.
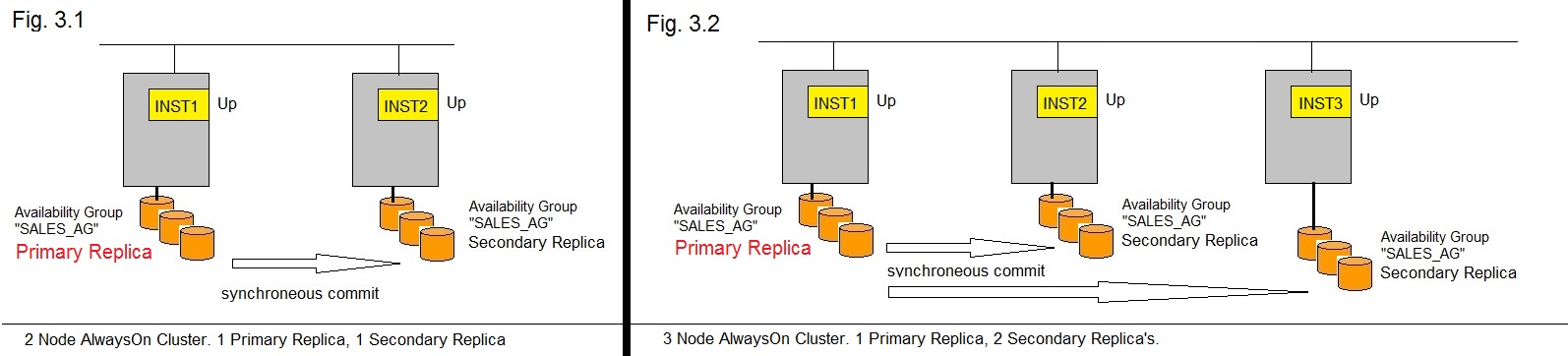
Fig 3. A few AlwaysOn Cluster examples.
As you can see in figure 3, you can have an "AlwaysOn" cluster with more than 2 Nodes (ofcourse).
In figure 3.2, you see one Primary Replica (under SQL Server Instance "INST1"), and 2 Secondary Replica's, under
SQL Server Instance "INST2", and SQL Server Instance "INST3", respectively.
In SQL 2012, you can have up to 5 Secondary Replica's, of which 2 Secondary replica's are updated from the Primary
using the "synchroneous commit" implementation, which makes those Replica's fully identical to the Primary at all times.
So, if you want, you can have 3 Replica's (1 Primary, 2 Secondaries) which are fully identical at all times.
You can also use the "asynchroneous commit" implementation, which might introduce a small "lag" at a Secondary replica,
since it is not mandatory that transactions complete at the same time at the Primary and Secondaries.
Having the "synchroneous commit" implementation in place, means that an automatic Failover to a Secondary Replication will work,
whenever a problem arises at the Primary Instance. In such a case, a "role switch" occurs, and a (preferred) Secondary replica
becomes the Primary Replica.
Having Secondary Replica's is ofcourse important for HA.
Per default, a Secondary Replica is not open for read access. However, you can alter this property, so that the Replica
becomes available for "Reporting", or for "Backup services".
Availability Groups include support for "read-only access" to one or more secondary replicas (readable secondary replicas).
Remember that an Availability Group contains one or more databases. So, the Primary Replica (of the Availability Group),
contains the same number of databases, and the same holds for all Secondary Replica's.
You can change the property of a Secondary Replica to "readable", using the Management Console, or a TSQL statement.
See Chapter 5 for more information.
Notice, that for the SQL Server Instances themselves, it holds that they are always active (up and running).
Apart from an "automatic Failover", you can also manually switch roles between the Primary and a Secondary Instance.
For this, you can use the Management Console (gui), or TSQL, or Powershell. See Chapter 5 for more information.
Active/passive and active/active Clustering for AlwaysOn.
The terms does not seem to apply for AlwaysOn Clusters. But it certainly does hold for "standard SQL Clusters".
Well, does it really not apply for AlwaysOn Clusters? In section 3.3 we will see a different opinion.
In the mean time, let's see what it means in standard SQL Clusters.
After that, we will revisit AlwaysOn again..., with respect to "Active/Passive" and "Active/Active".
3.2 How it is in standard SQL Failover Clustering.
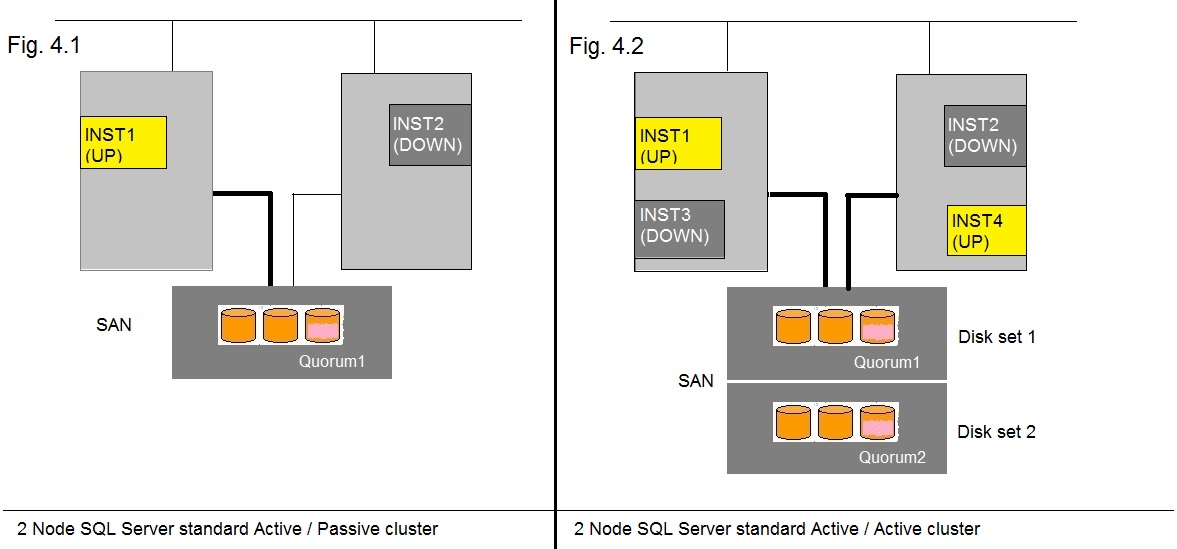
Fig 4. "Active / Passsive" and "Active / Active" in a standard SQL Cluster.
This time, we take a look at "the SQL Server standard Failover cluster" (not AlwaysOn).
Fig 4.1 above, is just the type we already know so well.
So, one Instance is active. The second Instance is down. The first Instance owns all resources,
like the "Virtual (service) IP", and the shared Disks on the SAN etc..
Only at failover, the second Instance will start, and becomes the owner of all resources, and resumes service.
Ofcourse, either INST1 or INST2 is active, but nomatter which one is "live" now, they work on the same set of database.
This is what we call an "active/passive" cluster, since only one Instance is active, and the other not (it's even down).
It's just waiting for a failover event.
One drawback of this setup, is that Node 2 is completely "idle". It's just the price to pay for redundancy and High Availability.
Now, INST1 and INST2, are like "two sisters". Only one is active, but that one will always work on the database
stored on the "shared" disks on the SAN.
Since many don't like having a complete idle system, you can install two other sister SQL Server instances,
which will operate on a complete different set of resources, like a different VIP and different
LUNs on the SAN.
Actually, it boils down to the fact that you install a Second (independent) Cluster on those two nodes, using it's
own Instances and Resources.
Thus suppose you originally had the cluster "SQLCLUS01" with it's instances "INST1" and "INST2", then next to it
you had to install the second cluster "SQLCLUS02" with it's instances "INST3" and "INST4".
Figure 4.2 tries to depict that. As you see in fig. 4.2, for example another set of LUNs were installed.
So INST1 (or INST2) will work with "Disk set 1" (also with it's own quorum disk).
So INST3 (or INST4) will work with "Disk set 2" (also with it's own quorum disk).
So, INST1 and INST2, work with one set of databases (just like a standallone SQL Instance would do).
And INST3 and INST4, work with a complete different set of databases (just like a another standallone SQL Instance would do).
Note that allways one Instance of such "sister pair" is active. At failover, one node runs two Instances.
For example (refer to fig. 4), suppose Node 1 crashes. INST1 is thus unavailable, and sister Instance INST2 will start on Node 2.
But on Node 2, INST4 was already running. So, now we have both INST2 and INST4 running on Node 2, but each one
operates on it's own set of databases.
This is what we call an "active/active" cluster.
Note that in an "active/active" setup, each node must be powerfull enough to support both services.
This is the "traditional" situation anyway, like in Windows Server 2008 + SQL Server 2008 or SQL Server 2012.
Thanks to new disk technology in Windows Server 2012, another variation is possible too, and later more on that.
3.3 AlwaysOn "revisited" with respect to Active/Passive and Active/Active.
Thanks to section 3.2, we now understand what Active/Passive and Active/Active means with standard SQL Failover Clustering.
Now, you can rightfully claim that an AlwaysOn Cluster can easily be configured in an Active/Active configuration.
This is different news than what I said in section 3.1.
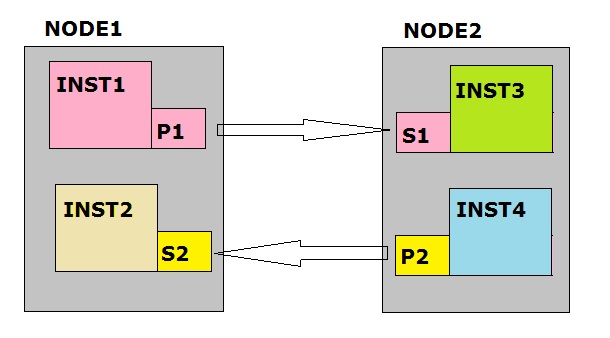
Just take a look at the figure below. Isn't that actually a great example of "Active/Active"?
Fig 5. An AlwaysOn Failover Cluster in "Active/Active" configuration.
In figure 5: P[n]: Primary Replica, S[n]: corresponding Secondary Replica.
4. Setting up an AlwaysOn Failover Cluster and Availability Groups.
Since Windows Server 2008, setting up an "Windows Failover Cluster" is really not so complex anymore.
After the above is created, creating a SQL Server 2008 (standard) Cluster (on top of the "Windows Failover Cluster") is also not too hard.
Since "AlwaysOn" was availble since SQL 2012, you can create a AlwaysOn cluster on top of a "Windows Server 2008 Failover Cluster",
or a "Windows Server 2012 Failover Cluster".
A good description of the process can be found in many great articles on the Internet, with great illustrations and screenshots.
I will not describe the setup, but if I may, I suggest you take a look at the following two Internet articles.
If you want a few gentle introductions on how to setup a "Windows Failover Cluster" and on top of that, an "AlwaysOn Cluster", you might take a look
at the following blogs/articles. The first one is very easy, and can be read in minutes. The second one (3 parts), provides for
more info, and takes a bit longer to study, but still is great stuff to read.
Hopefully, you have read an article, such as listed above (illustrated with nice screendumps etc..), which provide a very good intro
in setting up a "Windows Failover Cluster" and on top of that, an "AlwaysOn Cluster".
However, I have a few additional notes from myself too. This just applies for a regular setup, and no "cloud stuff".
Suppose you want to create the 2 Node AlwaysOn Cluster "SQLPRDCLUS03". The Cluster name is choosen like that, since, for example, you already have
the clusters SQLPRDCLUS01 and SQLPRDCLUS02 in place, and they just seem like good illustrative names.
Note: The "PRD" in the name designates "production", while "TST" or "ACC" would be good for Test- or Acceptance systems.
Suppose, you plan to use the machines "SQL03N1" and "SQL03N2" as the two intended Nodes of this new Cluster.
=> First, why is a "Clustername" neccessary, and registered in AD and DNS?
- The two Nodes, if they communicate, will identify themselves as being members of this Cluster,
and thus do not belong to some other Cluster. In the registry of those nodes, you will see references
of the fact they are member of "SQLCLUS03". In the network packages they exchange during InterCluster communications, you will find the Cluster name too.
- Secondly, "everything" that has to be authenticated and verified, needs to be registered, for example in AD.
That holds for user accounts, machines, and indeed, a cluster as an identifyable object, too.
- Thirdly, among possibly many other clusters, you need to administer "SQLPRDCLUS03" once in a while, so you need
a way to find it. That is possible thanks to the registration of "SQLPRDCLUS03" in AD and DNS.
The Cluster needs to have an IP too, so that for example your management tools can locate the Cluster, and you
can work with it.
In fact, when you connect to a cluster with some administrative utility (like the "Failover Cluster Manager"), you are
just connected to one of it's Member Nodes.
Or, using some cluster aware administrative utility, you can also use the Name or IP of one of the Membernodes,
which connects you to the clustersoftware on that Node.
=> (Minimal) Needed IP addresses.
The "Cluster" itself needs a fixed IP, registered in DNS.
Each node needs (at least) two fixed IP's: that is, per Node, one for the interface to the Public subnet,
and one for interface to the the Private (heartbeat) subnet.
Per Availability Group, a socalled "listener" is configured.
This listener has a "name", and uses a "Virtual IP", which both are registered in DNS too. The clients are configured to
connect to the "listener name" which points to the Primary Replica. Whenever a "role" switch occurs (that is, a Primary Replica
fails, and a Secondary Replica on another node becomes the Primary Replica), the listener "failsover" as well,
now pointing to the new Primary Replica. Well, maybe the term "failover", applied to the listener, is not fully satisfactory. It does not really
failover, but it is simply aware of the current Primary- and Secondary Replica's, and it can route clientrequests to right Instance.
By the way, the term "failover" for the Replica's themselves, is appropriate, ofcourse.
So, an example of used IP's in a simple 2 node setup, using one "Availability Group" ( for example "sales_ag") over two Replica's
(the Primary on Node1 and the Secondary on Node2), with one "listener" (for example "lsnr_sales_ag"), might be like the following table.
Cluster "SQLPRDCLUS03" IP address
145.15.20.150
SQL03N1 Public IP
145.15.20.151
SQL03N1 Private IP
192.168.1.10
SQL03N2 Public IP
145.15.20.152
SQL03N2 Private IP
192.168.1.11
Listener "lsnr_sales_ag" VIP
145.15.20.153
So, suppose you had a second Availability Group, then you had a second listener too, with a VIP like for example "145.15.20.154".
Notes:
- Netcards for production systems, are often "teamed", meaning that actually two interfaces work together.
This can then be in a "loadbalancing mode" (both work at the same time), or in a "failover mode" (one does
nothing until the other fails, where the idle one then takes over).
- Such setups, like shown in figure 1, are using "switches" to connect the net interfaces to the Networks.
However, in a 2 Node setup, for the "private network", even a simple crossover cable might work (!).
- In "AlwaysOn" Failover clusters, there is usually no SAN in place. In "standard" Failover clusters, usually a SAN
is used for storage. In such a case, other cards need to be installed and configured like HBA, or iSCSI.
=> Activate the "AlwaysOn feature" on all Instances.
Suppose you have the Windows Failover Cluster running, and on each node, also a SQL Instance
is installed. Before you can create Availability Groups (and Replica's),
You must first enable that feature on all SQL Instances that will play a role in your AlwaysOn Cluster.
Fortunately, it's very easy to do so.
Simply use the "SQL Server Configuration Manager". Then, rightclick the Instance on which you want to enable "Availability Groups"
and choose "properties". In the following dialogbox, choose the Tab "Availability Group", and activate the feature.
An important reason why it's not "on" in the first place, has to do with Microsoft's "small surface" policies.
You can see this sort of reasoning with their recent Operating Systems too. You get a relatively "bare" system and you must explicitly
enable features and or install "roles" if you need them.
This ensures that the system has a lower attack surface, seen from security perspectives.
=> Carefully Plan your Availability Groups, and where to put Replica's.
Technically, creating Availability Groups (and thus Replica's) is easy. You already know that, or you will see,
if you use the Graphical Management Studio (SSMS). So, technically, there should be no problem at all.
However, choosing the right databases for your Primary, and where to store your secondary Replica's, the sync model,
how many Secondaries etc.., is probably the hardest part. In short, a good planning phase is the most work.
Furthermore, it would be very handy that you use the same "paths" for database files, transaction log files,
for all databases who will be member of an Availability Group, so that those are equal on the Primary Server and the Secondary (or secondaries).
Although in principle, they may differ, you make it much more easy for yoursef if the same driveletters and paths are used.
Although after the Replica's are up and running, you will have HA, having a good backup/restore policy is paramount.
So, even if HA is in place, it does not dismiss you from the usual backup duties.
A good backup/restore policy needs to be created too.
In short: plan thouroughly.
=> Creating Availability Groups, and Replica's.
Using the Management Studio (SSMS), you can't go wrong here. (In chapter 5, I will present TSQL commands to achieve the same.)
As an outline:
On the primary Instance, make sure there is low (or preferably none) activity on the databases.
On the primary Instance, make sure that the database are in "Full recovery mode".
Create a full backup of the source databases, and restore them on the secondary Instance.
If needed, also use Transaction Log backups, and restore them after restoring the Full backups.
It's often not needed to perform this step. TLog entries have unique numbers (lsn's), and SQL Server "knows"
which lsn's to transfer from the Primary to the Secondary.
From SSMS, right-click the "Availability Groups" container. Choose "new" and it will start a Wizard.
Create an Availability Group, using a appropriate name. Assign your databases to that group.
From the Wizard, connect to the Secondary Instance.
The wizard guides you further along, and wrap it up....
This concludes this simple Intro. What's left is chapter 5, with a number of example TSQL commands,
illustrating how to Manage "AlwaysOn", and some appendices.
5. Managing AlwaysOn using TSQL (including Failover).
Here you will find some main TSQL statement examples, further illustrating managing AlwaysOn.
For explanations and the general theory of AlwaysOn, please see Chapters 1 to 4.
In the following examples, the Availability Group called "SALES_AG", will serve as our main example Availability Group.
5.1 Failovers.
Please do not view this section as a "troubleshooting guide". It's really far from it. Remember that this note is just an Introduction?
You will only see some TSQL statements with a minimum of comments.
Whether you are at the point to perform a planned failover, of one or more Availability Groups, or,if you face an error condition, where only a forced failover seems to be the only option...,
I strongly suggest you always take a few minutes to check:
The "Failover Cluster Manager" events.
The regular SQL Server logs of the Primary- and the Secondary Instance.
Windows Server Application- and System logs (event viewer).
Run the systemview queries (3) and (5) as listed in Appendix 1 on the Primary Instance.
5.1.1 Performing a manual "Planned" failover of an Availability Group:
In this case, there is no error condition. You only want to perform a failover, because of,
for example, performance reasons, or planned maintenance of the current Primary Instance (or Node).
Connect to an Instance that has a Secondary Replica of the availability group that you want to Fail over:
ALTER AVAILABILITY GROUP SALES_AG FAILOVER;
If you run the systemview queries (3) and (5) as listed in Appendix 1, then take special note of the columns:
- "is_failover_ready": value = 1: database is synchronized and ready for failover.
- "synchronization_state_desc": value = sysnchronized": database is synchronized and ready for failover.
5.1.2 Performing a "Forced" failover of an Availability Group:
There is a large difference between a "planned" failover, compared to the situation where you need to perform
a "forced" failover. Clearly, in latter case, some sort of a serious error condition has occurred.
For an important Production environment, you should be very carefull using a forced failover to a Secondary.
Always check the logs mentioned at the beginning section 5.1, first,
because you need information about the system "as a whole" in order to make a wise decision.
In case you have decided to perform a forced failover:
Connect to an Instance that has a Secondary Replica of the availability group that that needs to Fail over,
(or to achieve a "role switch"), and use the statement:
ALTER AVAILABILITY GROUP SALES_AG FORCE_FAILOVER_ALLOW_DATA_LOSS;
Some further comments on possible "data loss":
If you use the "synchroneous commit" mode, you know that the state of the Primary and Secondary must be the same.
A transaction can only succeed, if the Primary, and Secondary, both have comitted that transaction.
It's also a requirement for "automatic failover". If transactions cannot succeed on the Secondary, then the system
should stall.
Anyway, you should be confident that databases should be equal, on both sides.
However, using the "asynchroneous commit" mode, it allows for a small lag at the Secondary. The Primary and Secondary,
in normal conditions, are usually "very close" in their states, but possibly a small lag exists at the Secondary.
But, the lag can be relevant to your business, and if so, then using the clause FORCE_FAILOVER_ALLOW_DATA_LOSS
might be problematic to make a Secondary the Primary.
If the Primary AG is still good and available, then you might consider re-creating the Secondary AG again.
If the Primary AG is "damaged", then you might consider FORCE_FAILOVER_ALLOW_DATA_LOSS anyway, to force a "role" switch,
and re-create a Secondary again.
But this scenario is actually a bit "theoretical". Although in principle it's all true, having an actual dataloss is quite unlikely.
Also, it's very unlikely that you are so unlucky to have a "truly" unsolvable sitution. But IT=IT and Murphy laws are true.
Although AlwaysOn is really "HA", at all times you should have a schedule of full backups, in combination with differential backups
and/or transactionlog backups.
Only that, will garantuee you can "go back" to a recent consistent state.
5.2 A few examples on Managing AG's.
5.2.1 Adding a Database to an AG:
From the Instance that hosts the Primary Replica:
ALTER AVAILABILITY GROUP SALES_AG ADD DATABASE HR;
5.2.2 Removing a Database from an AG:
From the Instance that hosts the Primary Replica:
ALTER AVAILABILITY GROUP SALES_AG REMOVE DATABASE HR;
5.2.3 Creating an AG:
Suppose you have the databases "HR", "Sales", and "Inventory".
Next, suppose you want them to failover like a "unit", so an Availability Group is the right answer to that.
Suppose that what you see is the Primary Instance, is SQL03N1\INST1.
What you see as a Secondary Instance, is SQL03N2\INST2.
Then the following might be a TSQL statement to create the Availablity Group "SALES_AG".
However, more work needs to be done to get full functioning Replica's, for example creating a listener, and joining
the Secondary Replica from the Secondary Instance.
Perform the following on the Primary Instance:
CREATE AVAILABILITY GROUP SALES_AG
FOR
DATABASE HR, Sales, Inventory
REPLICA ON
'SQL03N1\INST1' WITH
(
ENDPOINT_URL = 'TCP://sql03n1.antapex.org:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL
),
'SQL03N2\INST2' WITH
(
ENDPOINT_URL = 'TCP://sql03n2.antapex.org:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL
);
Perform the following on the Secondary Instance:
ALTER AVAILABILITY GROUP SALES_AG JOIN;
Appendices
Appendix 1: Systemviews related to AlwaysOn.
The following is about querying the metadata, or systemviews, of a SQL 2012/2014 AlwaysOn Cluster.
For example, take a look at:
select * from sys.dm_hadr_availability_group_states
select * from sys.dm_hadr_availability_replica_states
select * from sys.dm_hadr_database_replica_states
select * from sys.dm_hadr_database_replica_cluster_states
select * from sys.dm_hadr_availability_replica_cluster_nodes
select * from sys.dm_hadr_instance_node_map
select * from sys.dm_hadr_name_id_map
select * from sys.dm_tcp_listener_states
select * from sys.availability_groups
select * from sys.availability_groups_cluster
select * from sys.availability_databases_cluster
select * from sys.dm_hadr_instance_node_map
select * from sys.availability_replicas
select * from sys.availability_group_listener_ip_addresses
select * from sys.availability_read_only_routing_lists
select * from sys.availability_group_listeners
Ofcourse, quite a few of them, can also be used to monitor, for example to view the current state of the AG's, the synchronization states,
and other "health" information.
Just try the queries, then use the queries with selections of some columns of interest. Then you might try some joins, and see
what can be usefull in your situation.
Here are a few of my own queries and joins:
(1). Which databases reside under which AG:
select substring(g.name,1,20) as "AG_Name", substring(d.database_name,1,20) as "Database"
from sys.availability_groups_cluster g, sys.availability_databases_cluster d
where g.group_id=d.group_id
(2). Which databases reside under which AG under which Instance:
select substring(g.name,1,20) as "AG_Name", substring(d.database_name,1,20) as "Database", n.instance_name
from sys.availability_groups_cluster g, sys.availability_databases_cluster d, sys.dm_hadr_instance_node_map n
where g.group_id=d.group_id AND g.resource_id=n.ag_resource_id
order by n.instance_name
(3). Checking the Health of the Replica's on an Instance:
select replica_id, substring(db_name(database_id),1,30) as "DB", is_local, synchronization_state_desc, synchronization_health_desc,
log_send_rate, log_send_queue_size
from sys.dm_hadr_database_replica_states
(4). Showing Availability Groups, and their listeners and VIP's:
select substring(g.name,1,20) as "AG name" , l.listener_id,
substring(l.dns_name,1,30) as "Listener name", l.port,
substring(l.ip_configuration_string_from_cluster,1,35) AS "VIP"
from sys.availability_groups g, sys.availability_group_listeners l
where g.group_id=l.group_id
(5). Checking if the Secondary Replica's on INST3 are "good" to perform a Fail Over. See also query (3).
select * from sys.dm_hadr_database_replica_cluster_states
where replica_id=(select replica_id from sys.availability_replicas
where replica_server_name ='INST3')
-- Other queries:
select replica_id, database_name,is_failover_ready
from sys.dm_hadr_database_replica_cluster_states
select substring(group_name,1,20) as "AG_Name",
substring(replica_server_name,1,35) as "Instance_Name",
substring(node_name,1,30) as "Node_Name"
from sys.dm_hadr_availability_replica_cluster_nodes
select substring(dns_name,1,30) as "DNS_LIstener_Name", port,
ip_configuration_string_from_cluster from sys.availability_group_listeners
select replica_id, substring(replica_server_name, 1,30) as "REPLICA_Server_Name",
substring(endpoint_url,1,30) as "Endpoint", availability_mode_desc
from sys.availability_replicas
Appendix 2: Some info on Windows Failover Cluster Repairs.
Here is a note that tries to say something "useful" on Windows Failover Cluster troubleshooting and Repairs.
It's not about SQL Clustering, or AlwaysOn, but instead, it focusses on Windows Failover Clustering.
It's not "great" or something, but if you want to try it, then use this link.