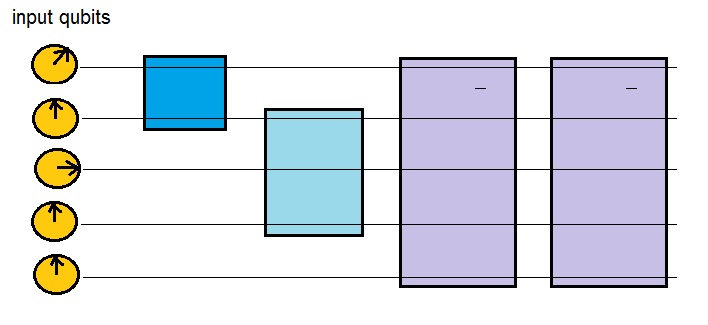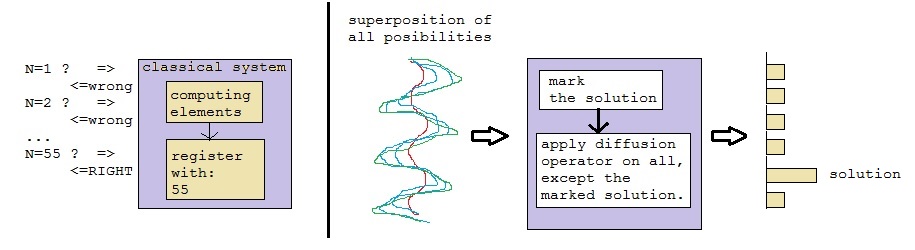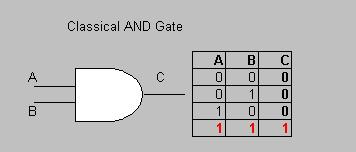
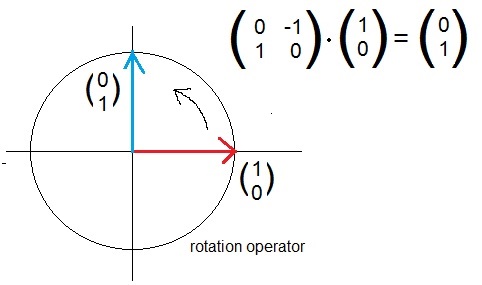

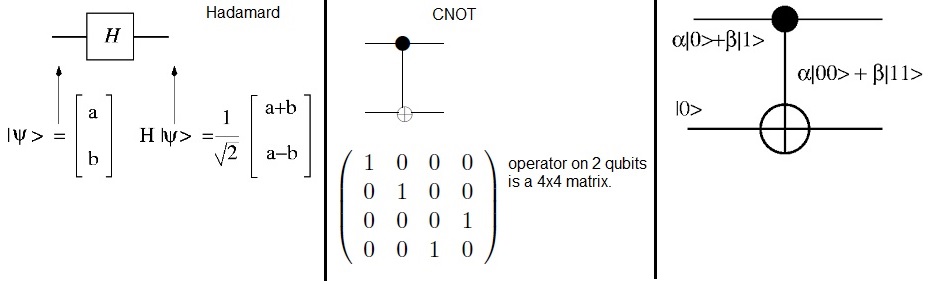
| B | = | |B > | = |
┌ b1 ┐ │ b2 │ └ b3 ┘ |
| <A|B> | = | [a1,a2,a3] | · |
┌ b1 ┐ │ b2 │ └ b3 ┘ | = | a1b1 + a2b2 + a3b3 |
|
┌ a1* ┐ │ a2* │ └ a3* ┘ |
|
┌ a11 a12 a13 ┐ │ a21 a22 a23 │ └ a31 a32 a33┘ |
┌ B1 ┐ │ B2 │ └ B3 ┘ |
= |
┌ a11*B1+a12*B2+a13*B3 ┐ │ a21*B1+a22*B2+a23*B3 │ └ a31*B1+a32*B2+a33*B3 ┘ |
= |
┌ C1 ┐ │ C2 │ └ C3 ┘ |
| [ A1 A2 A3 ] |
┌ a11*B1+a12*B2+a13*B3 ┐ │ a21*B1+a22*B2+a23*B3 │ └ a31*B1+a32*B2+a33*B3 ┘ |
= | [ C1 C2 C3 ] |
| |B > < A| | = |
┌ B1 ┐ │ B2 │ └ B3 ┘ |
[ A1 A2 A3 ] | = |
┌ B1*A1+B1*A2+B1*A3 ┐ │ B2*A1+B2*A2+B2*A3 │ └ B3*A1+B3*A2+B3*A3 ┘ |