Version : 1.1 - Ready Date : 20/01/2013 Level : Basic By : Albert van der Sel
This note is a quick intro in Unix/Linux shell scripting. Because it's fast, it also inevitably means that it is short,
and incomplete.
It's not for experienced SysAdmins.
No..., but it might be useful for someone who wants to get into basic shell scripting.., fast.
You do do not need to know much beforehand. I only want you to understand what a terminal session is, and how
to get to a "prompt" (instead of only working with GUI's). It would also help if you know a bit about unix/linux
file-permissions (the "-rwxrwxrwx" stuff), and a little bit of "vi", the "editor" to create textfiles.
But, on those subjects, a microscopic intro is included in chapter 1 too.
Scripting is the subject of chapter 2. So what's in chapter 1? I think it is a sort of "foundation",
since for shell scripting, knowledge of tools like "sed", "awk", "tr", "grep", and a few others, is really needed.
Furthermore, some knowledge about filemodes (security), and how to use the "chmod" command to make a file
executable (for example), is pretty much mandatory too.
Main Contents:
Chapter 1. A "foundation" first.
1.1 A few general things to know first.
1.2 Filemodes (or "permissions").
1.3 The "chmod" command to change access rights (the "flags").
1.4 A few words on viewing and creating/modifying files.
1.5 Wildcards.
1.6 The "find" and "grep" commands.
1.7 Pipeline and Redirecting.
1.8 The "sed" and "tr" commands.
1.9 The "awk" command.
Chapter 2. A few basic notes on Shell scripting.
2.1 Some "housekeeping".
2.2 Variables.
2.3 Conditionals: The "if" and "case" statements.
2.4 Several types of "Loops."
2.5 Parameters.
Chapter 1. A "foundation" first.
1.1 A few general things to know first.
If you started a "ssh" terminal to a remote Unix or Linux host, then after logging on, usually
a simple "$" prompt appears if you are an "ordinary" user of the system.
Ofcourse, you might also have a unix, or linux system, installed on a (local) personal system.
By convention, if you are "root" (or the superuser, or the big boss), the prompt often is a "#" symbol.
You are probabably interested in "where you are", or "your path", in the filesystem, so you immediately enter the "pwd"
command to find out your location. Big chance, you are in the "/home/yourusername" directory. However, if you are somewhere else,
there is no problem at all. If not in the home directory, you can always try the "cd ~" command, which usually gets
you to your homedir (if you have one).
If you indeed have a simple "$" prompt, you might try this command: PS1='$PWD>' which should change the prompt, and show you
the "path" inside the prompt,like "/home/mary>", which might be a bit more comfortable.
But if it didn't work, then don't worry about it.
But many Linux distro's already per default shows a friendly prompt like "[albert@STARBOSS /home/albert $]".
which shows your account, the machine name, and location in the filesystem.
This "PS1" thing, is the name of one of the "environment variables" which are defined for your session.
To see all those variables, try the "env" command. Or to see just one, like the "path" variable, try "echo $PATH"
$ pwd
/home/mary
$ PS1='$PWD>'
/home/mary> env
..
shows all the environment variables you have now..
$ echo $PATH
Shows the directories (the paths) which your shell will search if you enter any command..
When you entered the commands as shown above, you are having a interactive session with your "shell", which is an interpreter for your commands.
It responds to the commands you key in, but it also starts and executes your shell scripts.
It depends a bit on what Operating System you work, but often the socalled "bash" shell is pretty default on Linux, while
on many Unix systems, "sh", "korn shell" or "bash" are often pretty default too. Most shells do not differ too much, at least
not for the scope of this note. Some folks say that some shells are a (tiny) bit better equiped for certain tasks,
but when it comes to "just" entering interactive commands, or creating shell scripts, the differences are not dramatic.
Any Unix or Linux Operating system, has hundreds (or even thousends) of commands. There are real System Administration commands
for example, to set kernel parameters, to tune memory, or to add disks etc.. etc..
They can be used in shell scripts too, as many SysAdmins do. However, the "typical" general purpose scripts are often concerned around
processing of files in the most general sense. For example, you as a scripter, must process files so that their format get changed,
or add/remove parts from the files, or send them to another machine based on some criteria, or do something based on the last access date/time etc.. etc..
1.2 Filemodes (or "permissions").
This is an important subject. In any Operating System, files and directories are protected by access rights.
In Unix/Linux, we have "filemodes" and "acl's", but the filemodes are most often associated with access rights.
In any directory, try the "ls -al" command, in order to get an extended file listing (with all attributes) in that directory.
Now, you might see stuff like this:
$ ls -al
-rw-r----- mary dba 18 jun 1231 readme.txt
-rwxrwxrwx mary dba 21 apr 2211 foreverybody.txt
-rwx------ mary dba 28 feb 8744 testscript1.ksh
-rwxr-x--- mary dba 19 feb 7251 testscript2.ksh
I want you to focus on the "-rwx rwx rwx" stuff here. In Unix/Linux, we have the following file/directory permissions (or also called "filemodes"):
r = read.....(like being able to "read" or "open" a file, but not being able to modify it)
w = write....(being able to "write" or "change" a file)
x = execute..(being able to "execute" a file if it's indeed executable)
- = nothing granted
Now, you will notice three "blocks" of three "flags" each, say for example "rwx rwx rwx" or for example "rw- rw- r--".
If a flag is a "-" somewhere in such a string, it means that a permission is not granted.
- The first three flags, apply to the "user" rights (which is, in the above listing, "mary).
- The second three flags, apply to the "group" (where the user is member of, like "dba" in the above listing).
- The third three flags, apply to "Everyone" (or sometimes also called "the world")
-------------------
|user |group|world|
-------------------
|r w x|r w x|r w x|
-------------------
So, as a few examples:
A file like "readme.txt" has rw (read and write) for mary, and r (read) for the dba group (where mary is member of). Everybody else has no access.
A file like "testscript2.ksh", has rwx (read and write and execute) for mary, and r (read) and x (execute) for the dba group.
So, as another example, if you see some file (in some directory) listed like so:
-rw-rw---- mary hr 19 dec 44788 personell.doc
Then it means that the user mary has rw permissions to the file "personell.doc", and so has the group "hr". But nobody else can access that file.
1.3 The "chmod" command to change access rights (the "flags").
If you are the owner of a file, you must be able to change the access rights to that file. Maybe you want the group
where you are member of, to be able to read the file too. Or, maybe you have created a script, but it's not executable yet,
meaning that the "x" flag is still missing. For this, you can use the "chmod" command.
It's real easy. Just add (+) or remove (-) the "flags" as you want them to be.
Examples:
Suppose a file has the following flags, but you want the group to have "rw" as well:
$ ls -al
-rw------- mary dba 22 dec 2231 readme.txt
$ chmod g+rw readme.txt
$ ls -al
-rw-rw---- mary dba 22 dec 2231 readme.txt
Suppose a file has the following flags, but you want it to be executable for you as well:
$ ls -al
-rw------- mary dba 22 dec 2231 myscript.ksh
$ chmod u+x myscript.ksh
$ ls -al
-rwx------ mary dba 22 dec 2231 myscript.ksh
Suppose a file has the following flags, but you think that the group has too many rights. So, you want the "w" and "x" be
revoked for the group:
$ ls -al
-rwxrwx--- mary dba 22 dec 2231 myscript.ksh
$ chmod g-wx myscript.ksh
$ ls -al
-rwxr----- mary dba 22 dec 427 myscript.ksh
So, "chmod" can be used with the "+" to add permissions, and with a "-" to revoke permissions.
In general use "chmod" like so:
chmod [u][g][a] + or - [r][w][x] filename (where u=user; g=group; a=world or everyone)
There is another way (or quicker way) to get the same results. Instead of explicitly using u/g/a and r/w/x in the command,
you can simply use "numbers" to denote the total of flags. Here is how it goes. First, watch this internal unix definition:
1 = execute
2 = write
4 = read
Execute and read adds up to: 1+4=5.
Read and write are: 4+2=6.
Read, write and exec adds up to: 4+2+1=7
So, if you would do "chmod 640 filename" it means 6 (rw) for the user, 4 (r) for the group, 0 (nothing) for everyone.
Here are a few examples:
Suppose you see the following flags on a file, namely "-rwxrwxrwx" which is too much. You want it to be "-rwxr-x---"
$ ls -al
-rwxrwxrwx mary dba 22 dec 427 myscript.ksh
$ chmod 750 myscript.ksh
$ ls -al
-rwxr-x--- mary dba 22 dec 427 myscript.ksh
So, the "7" for the user is "rwx" which is 4+2+1. The "5" for the group is "r-x" which is 4+1=5.
You see? Setting flags this way is pretty quick and efficient.
Suppose you see the following flags on a file, namely "-rw-------". You want it to be "-rw-r-----"
$ ls -al
-rw------- mary dba 22 dec 1527 myfile.doc
$ chmod 640 myfile.doc
$ ls -al
-rw-r----- mary dba 22 dec 1527 myfile.doc
Although you can "easily" calculate it yourself, here are a few "popular" filemodes:
Security note:
Now, this is just a humble note for learning shell scripting. So, I think you are probably working on a private system.
On a private system, you can do want you like ofcourse.
However, in general, always the "principle of least priviledge" should be followed.
This means: grant no more permissions on objects than is absolutely neccessary.
So for example, for "everyone" (or the "world") having access to files should not be done, or be highly exceptional.
1.4 A few words on viewing and creating/modifying files.
Shell scripts contain "plain text". In other words, they are just "ascii" files.
If we want to create a new script, or if we want to modify an existing script, we need an "editor".
One of the oldest and well-know editors, is "vi" (sometimes it's named "vim" on Linux systems).
So, we need a bit of knowledge of vi.
However, sometimes you just want to quickly browse through an ascii file. For this, we do not neccessarily need an editor.
The "cat" and "more" commands, enables us to view the contents of any ascii file (like a script).
But there exists not only ascii files on the filesystem. Also, many binary files live there too.
So, if it's not obvious from the name of the file, what type of file it is, we need a way to check the filetype.
Determining the type of file:
For this we can use the "file" command. It cleary shows you what the filetype is, like ASCII or binary.
For example:
$ ls -al
-r-x------ root bin 17 jan... 886 myscript.sh
-r-x------ root bin 23 feb..23674 gatekeeper
$ file myscript.sh
ASCII text
$ file gatekeeper
gatekeeper: ELF 32-bit LSB executable
Not all systems display exactly the same output, but it should be clear from the output whether or not we are dealing
with a text file or not. In the example above, the file "myscript.sh" is a text file which we can safely browse using "cat" or "more".
using the "cat" and "more" commands:
These two commands are great for viewing the content of flat files, like shell scripts.
They are very easy to use.
$ ls -al
-r-x------ mary dba 17 jan... 886 myscript.sh
-r-x------ mary dba 23 feb..34518 presentation.ppt
$ cat myscript.sh
The full content is displayed. However, if the file is large, maybe it does not fit on your screen, so maybe you only see
the last "screen" of that file.
Redirecting the "ouput" to the "more" command, shows you "one screen at the time" everytime you press Enter.
$ cat myscript.sh | more
Here we used the "|" pipeline symbol, to connect two programs: "cat" and "more".
Usually, "cat" just simply dumps the content of a file to your screen. But by using a "pipe", "cat" now knows that
it must send the data to the "more" command, which shows the content "one screen at the time".
Using the "more" command by itself, is often even better.
It simply dumps the content of a flat file to your screen, one page at the time.
$ more myscript.sh
If you want to end the output before it's done, simply press "Ctrl-C".
A few words on the "vi" editor:
"Vi" is not the easiest editor around. Everybody starting with vi, will make many mistakes in the beginning.
That's really "normal".
Here are a few notes, that gets you started. But, folks have created tutorials which are at least 30 pages or so.
Using a normal account (not "root"), you probably have a homedir like "/home/mary" or so.
But maybe it's a good idea to create your first files in "/tmp", which is a sort of temporary workspace for everybody.
Ofcourse, "/tmp" is not the place for "permanent storage". Don't put anything in there of value.
Later on, after the first "trials" with vi, store your files at a better place, like your homedir.
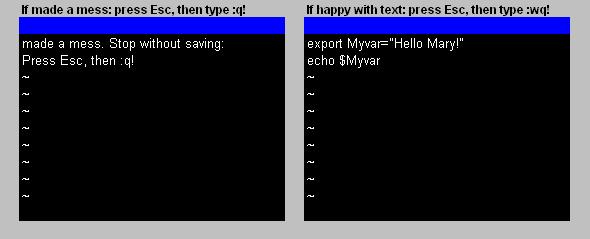
First, take notice of this. Vi uses two main "modi":
1. Command mode: If you press "Esc"
Then you can enter ":" and "q!" (from quit !). You will see those symbols at the left-bottom of the screen.
This tells vi to exit without saving anything. This is handy if you made a "mess" of the text.
Or, if happy with the typed text, you can enter ":" and a "wq!" (write quit !) and vi exits with saving the file.
2. Insert mode: If you press the "i" or "a" or "Ins".
In Insert mode, you can enter text. If ready, you can press Esc to go to Command mode to quit, or quit and save the file.
You can "toggle" between Insert and Command mode. Just press "esc" or "i" when you want.
Important: once you have a few lines of text, press Esc, and then you can "freely" use the cursorkeys to navigate through
the text, and place the cursor where you want it to be.
Fig 1. An example using "vi" (or "vim").
Shall we try to create a file?
$ cd /tmp
This "moves" you to the "/tmp" directory, which you can verify using the "pwd" command.
Now start creating your first scriptfile called "myscript.sh". So use the command "vi myscript.sh" (remember that vi might be named "vim" on your system).
$ vi myscript.sh
Your editor starts. Essentially, you have an empty screen. Now press "i" to go to "Ins" mode which enables you to enter text.
Now, using your highest concentration possible ;-), you type in:
export Myvar="Hello Mary!" (press enter)
echo $Myvar (Now press Esc, and type :wq! to save the file)
Hopefully it worked. If so, congratulations !
Now, do the following:
$ ls -al myscript.sh
-rw-r----- mary dba 13 jan... 36 myscript.sh
$ chmod u+x myscript.sh
$ ls -al myscript.sh
-rwxr----- mary dba 13 jan... 36 myscript.sh
$ ./myscript.sh
You see that I made the script executable (for the user/owner) by using the "chmod u+x" command.
Indeed, the "x" flag was added. Then I called the script, that is, executed the script.
Note:
If you could not start "vi" (or "vim"), then maybe it's not on your system. However, that's not very likely.
You might try this from the prompt: export EDITOR=vi
Try again if you can start "vi" this time.
Optional exercise: Now as a further "vi" excercise:
Start "vi" again using a filename of "test" (vi test).
-Press "i"
-Now type the 1st line: aaa aaa aaa (press Enter)
-Now type the 2nd line: bbb bbb bbb (press Enter)
-Now type the 3rd line: ccc ccc ccc (press Enter)
-Now type the 4rd line: ddd ddd ddd
-Press Esc
-Type :wq! to save it, en exit vi. Now, we do not save it any further, so if you mangle the file
in the following exercises, just quit vi and load the file again.
.Move the cursor around using the "arrow keys". Note that you can freely move around.
.Now place the cursor at the third "a". Press "d". Is the third "a" removed? (Maybe you must use "x" instead of "d").
.Press "i" and type "a" and press Esc again. You have that third "a" back again?
.Now place the cursor somewhere at second line. Press "d". Press "d" again. What happens?
.Press Esc. Place the cursor at the 6th a. Press "a", press "a" again. What happens?
.Press Esc. Place the cursor at the 6th b. Press "i", press "b". What happens?
Maybe you should play around a bit in "this style".
1.5 Wildcards.
You do not have "practisize" the following example. If you read it, and understand what's happening, then that's fine enough for me.
Suppose in the "/home/abert" directory, we see the following:
$ ls -al
-rw-r------ albert dba 17 jan... 886 myscript.sh
-rw-r------ albert dba 23 feb..23674 abc.dat
-rw-r------ albert dba 11 apr... 982 personel.txt
-rw-r------ albert dba 19 aug..43674 config.dat
-rw-r------ albert dba 17 jan... 886 ftpfiles.sh
-rw-r------ albert dba 23 sep..73674 qm.txt
-rw-r------ albert dba 25 jan... 221 def.dat
-rw-r------ albert dba 15 jan..88674 accpres.ppt
drwxr-x---- albert dba 17 jun.....12 test
etc..
So, suppose a whole lot of files are inside that directory. Now, suppose there are a lot of subdirs too.
Here, we only see the subdir "test", but let's our imagination work here.
Famous "wildcards" in Unix (and many other Operating Systems) are the "*" and "?" characters.
Suppose I only want a listing of ".sh" files. Then I can use the "*" in the following way:
$ ls -al *.sh
-rw-r------ albert dba 17 jan... 886 myscript.sh
-rw-r------ albert dba 17 jan... 886 ftpfiles.sh
So, the "*" can replace one or more characters. It's a wildcard for one or more characters. It is as if we say
to the shell "I don't care what comes before the ".sh". Anything is OK. Just give me the listing."
Now, you can place the "*" anywhere you think it is usefull. For example, you can get a listing of "*script.sh" too.
This returns all files which has "script.sh" in their names, no matter what comes in front of it.
And something like this works too: "perso*". This returns everything with a name that starts with "perso",
no matter what is behind that string.
The "?" charcter is usefull to replace one (or more) character(s) by this wildcard. But, the more "?" inserted, the more
it starts to look like the use of "*". For example, you only want to see the accounting reports from 1990 up to 1999:
$ ls -al acc199?rprts.doc
Now, we only used the "ls" command up to now. But the same principle applies with all commands.
For example:
$ cp *.txt /tmp # copy the *.txt files from "/home/albert" to "/tmp"
Or, if I am logged on to the machine STARBOSS and I want to copy *.sh files to machine STARGATE, using the "scp" utility:
$ scp *.sh albert@STARGATE:/data/scripts
1.6 The "find" and "grep" commands.
These are two very powerfull commands. You can't leave home without them.
⇒ The "find" command:
This one is really great. For now, we will only see the simplest example of this command, namely just "finding" files.
But, very powerfull "exec" constructs exists, in combination with "find".
Let's start simple. Suppose in large directory tree, you want to find a specific file (or a set of files), and get it in a listing.
Just use find. Take a look at these examples:
$ find . -name "myfile.txt" -print
Here, the "." (the dot) tells "find" that it should start as from the current directory, and find "myfile.txt" throughout all subdirs too.
$ find . -name "*.dat" -print
Again, the "." tells "find" that it should start as from the current directory, and find all files with the ".dat" extension,
throughout all subdirs too.
⇒ The "grep" command:
You will find this one in allmost all scripts. It's very usable since it filters information from a bulk of data.
Let's take a look at a few examples.
You probably often have used the "ps -ef" command. On almost all Unixes and Linux distro's, it gives a full process listing.
Now, that can be a listing of hundreds of processes on a busy system.
In scripts, or from the prompt, you are often interested in one kind of process only. Then filter the data with "grep".
$ ps -ef
Gives an extended listing of all processes...
$ ps -ef | grep -i ora
Shows only those processes with the string "ora" in their name (if such processs is present).
$ ps -ef | grep -i syslog
Shows only those processes with the string "syslog" in their name (if such processs is present).
The "-i" argument means "case insensitive". You can leave it out, but then grep does NOT ignore "case".
You can use "grep" to search files too, for a certain string. For example:
$ grep Sally customers.txt
This will return only the records containing "Sally" from the file "customers.txt".
1.7 Pipeline and Redirecting.
⇒ Connecting programs through a pipe:
We already have seen examples of this in section 1.6. There we saw that the "ps -ef" command
produces a list of all running processes. It's default output device is the connected console (your screen),
which is called "stdio" (standard io).
However, using the "pipe" symbol "|", we can connect programs in such a way, that the output of the first program,
becomes the input of the second program. So, instead that "ps -ef" pushes it's list to your screen, it becomes the input
for "grep".
Usually, only two programs are connected this way. But you can add a second "pipe", and a third "pipe" etc..
For example:
program1 | program2 | program3
The output of program1 becomes the input for program2, and the output of program2 becomes the input for program3.
Some examples:
-- The output of "ps -ef" is fed to the "more" command:
$ ps -ef | more
-- The output of "ps -ef" is fed to the "grep" command:
$ ps -ef | grep -i syslog
-- The output of the "cat" is fed to the "grep" command, which is then fed to the print command:
$ cat customers.txt | grep "New York" | lpr
⇒ Redirecting output to a file:
Many commands produces some sort of listing, which often will be printed on your screen.
But you can "redirect" the output to a file instead, using the ">" redirection symbol.
Again, here is a utility with lots of power. However, most people only seem to use the "s" or "substitute" command.
Well, that counts for us too. It's just that replacing stuff (in a file, or string) is simply a often sought feature.
How does it work?
Let's create a small file with data. Goto "/tmp" (or your homedir). Then, using vi, create a file called "oldfile.txt"
having the following content. If you wonder about the "numbers" before some names: thats on purpose.
Sally Amsterdam
5Henry New York
99Carl Washington
Miranda Berlin
77Albert Amsterdam
Now imagine that it's a file containing thousends of records. Suppose that all "Berlin" fields must be "substituted" by "Munchen".
That's a simple task for "sed"
$ sed 's/Berlin/Munchen/' oldfile.txt > newfile.txt
$ cat newfile.txt
Sally Amsterdam
5Henry New York
99Carl Washington
Miranda Munchen
77Albert Amsterdam
So, when using the "s" (substitute) command, use "sed" like so:
sed 's/oldstring/newstring/' originalfile > newfile
The "/" is the "delimiter" which seperates the oldstring from the newstring (within the command), which is almost always OK.
So, this delimiter has nothing to do with the delimiter of fields inside the file (like a space, a tab, a ";" etc..).
It's only there so that sed can discriminate between "oldstring" and "newstring" on the commandline.
Sometimes however, the default delimiter "/" does not work. Just suppose you have a file listing all sorts of filesystem paths.
Here, a lot of slashes "/" can be expected. So, if you want to replace a certain path by another path (in the file), another delimiter
is needed. In such a case, you could try the "_" delimiter like in:
$ sed 's_/home/albert_/home/mary_' OldfileWithPaths.txt > NewfileWithPaths.txt
Remember that the oldfile.txt (which you created with vi) has some records with names with numbers in front of them?
Now, this could be seen in reality too. Maybe you get a file and you are asked to remove "all polution" (like numbers) from it,
so that the endresult is just a clean file with just simply names and cities, and all numbers removed.
This is how you can do it:
$ sed 's/[0-9]*//' oldfile.txt > newfile2.txt
$ cat newfile2.txt
Sally Amsterdam
Henry New York
Carl Washington
Miranda Berlin
Albert Amsterdam
Notice that we do not exactly have a "/oldstring/newstring/" really. Actually we only want to remove numbers.
So we want to "remove" stuff, and that stuff is not replaced by anything. That's why the "//" is empty.
The [0-9]* stuff is great in all Unix shells and programs. Anything that looks like a "range" [0-9], is taken as a range.
At runtime, it's expanded in all numbers 0,1,2,3,4,5,6,7,8,9. So, that's great !
The * is a wildcard, meaning "everything" here.
In effect we say to "sed": look at all fields ("*"). If you see anything in [0-9], replace it by "null" ("//").
⇒ The "tr" command:
The "tr" command is especially usefull for replacing characters in a file, or on any other input delivered to "tr", for example,
through a pipe from another program.
Now you might say that "tr" then has a lot in common with "sed". A bit indeed, but they do have different scopes.
"Sed" for example, is great for replacing a word (like a name) by another word, throughout a file.
On the other hand, "tr" is great for replacing a certain "feature, like replace small case letters to captital letters,
or removing to two consequetive spaces to one space, throughout a file.
Now that we have seen the use of a range (like [0-9]) when we discussed "sed", we don't let go of such fantastic feature,
since it can be used wih "tr" too (and that's true with most other unix utilities).
So, how is "tr" used? Some examples will clarify.
Go to your homedir, or to "tmp".
Use vi to create a textfile named "trtest.old" with the content as shown below.
Note: Take notice of the upper and lower casing of characters. That's on purpose. The extra two spaces in "PE TER" is on purpose too.
After you are done creating the file, we should have this content:
$ cat trtest.old
SALly
hENDRIck
PE TER
alBErt
Now let's see if we can replace all Upper case letters to lower case. We can use the following command for that:
But let's try another notation ! It's another way to write the same command.
Actually, It's quite stunning. Take a look at this:
$ tr "[A-Z]" "[a-z]" < trtest.old > trtest.new
Isn't cool to write commands in such a way? The "tr"command gets its input through the use of the "<" symbol.
This input is the file "trtest.old". Using the usual "redirection" symbol ">", the output goes to the file "trtest.new".
We have been busy on modifying files, but both "sed" and "tr" can get their input from a "pipe" as well, like so:
$ echo "AB CD efgHIJ KLM" | tr "[A-Z]" "[a-z]"
ab cd efghij klm
Here, the "echo" command pushes its data through the pipe to "tr", which replaces all Upper case with lower case characters.
1.9 The "awk" command.
The "awk" command is again such a utility with gigantic capabilities. It's almost a sort of "perl" environment by it's own!
Someone could write a 50 page introduction on "awk" with ease. And there are quite a few of them.
Awk is simply too large to do it justice in such a note as this. But, don't worry. Mosts scripts only use the
basic capabilities of "awk".
For the basic functionality of "awk", you might describe it as a processor for anything that produces rows and fields
that you want to be processed and/or formatted in some way.
We already have seen commands which were connected by a pipe. Indeed, often "awk" receives input that way and then starts
filtering and/or formatting the data the way you want it to be.
Often, in scripts you will find statements like this:
"some program" | awk '{print $1 $3}'
Here, "some program" pushes records through the pipe to awk. In the example above, awk then only prints the first and third record.
In this setup, "$0" represents the full record, "$1" the first field, "$2" the second field etc..
The program that delivers data to awk, can be anything. Like for example "ps -ef" which produces a process list, or a command
which lists Logical volumes with their attributes, or "cat", which opens a file and pushes the records to awk etc.. etc..
Here are a few examples:
$ echo "A B C D" | awk '{ print $1 $3 }'
Question:
Explain why we see AC as output.
But it's not true that awk is always used as "just a utility" in a "pipe". It can operate by itself too, directly.
Let's create a file with vi. Name it "custlist.txt", and put the following records in it:
Customer Month Debt
KLM June 1000
GM June 5000
KLM December 2000
Murphys November 10000
Let's try this:
$ awk '/KLM/ { print $0 }' custlist.txt
If you run that, you only get the records containting "KLM". So here awk functions as a filter for searching
certain records from a file.
Question:
Can you think of a simpler, but equivalent command, by just using "grep"?
Right. Now we have a good basis of general commands and concepts. Although we have not yet dealt with a number
of other usefull commands (like "wc -l" and others), I will explain those commands while we go through the example scripts.
Let's finally start with Chapter 2.
Chapter 2. Basic shell scripting.
As said before in the introduction, chapter 1 really is the basis for Chapter 2.
As you will see, "shell scripting" is easy. The real trick is, that you understand those remarkable shell utilities
like "sed", "tr", "awk", "grep" and a couple of others. So if you are in doubt, return to Chapter 1.
2.1 Some "housekeeping" first.
Here you see a simple example of a script.
#!/bin/sh
###############################################################################
# Purpose.......:Script wich searches the "myapp logfile" if any critical errors
# ...............are found. If found, a mail is send to the Operator.
# Author.......: Mickey Mouse
# Version......: 0.1
# Date.........: 11/11/2009
# Modifications:-------------------------------------
#...............-------------------------------------
#...............-------------------------------------
###############################################################################
if [ `cat /tmp/errlog.txt | wc -l` -gt 0 ]
then
mailx -s "Critical error found in myapp.log" operator@mycompany.org
fi
⇒ The "directive":
First, do you notice the first line "#!/bin/sh"? It tells your shell which "interpreter or shell" must execute
this script. It's always recommended to use it, to denote the right interpreter.
The #! is a directive for your shell which interpreter (or program loader) to use.
Since scripts are fairly portable across shells, you often "get away" with it, if you have left it out.
However, it's always possible that your script uses specific features from some shell, and there things
might go wrong.
So, suppose you always work with the "/usr/bin/ksh" shell, and your scripts are intended for the korn shell,
then use "#!/usr/bin/ksh" as a directive.
It's actually quite "universal". If you would create perl scripts, and you want to call the script just by it's name
from the unix/linux prompt, then use something like "#!/usr/bin/perl". In this case, your unix shell immediately knows it must
run perl with this script.
⇒ Some "housekeeping":
Any line that starts with "#", is a "comment" (except #!).
- You should always start your scripts with a block of usefull coments, like "the purpose" of your script,
the "version", the "Author", the "last modification date" etc..
It's really a help for someone who must support or maintain your scripts at a later time.
Now, the example above is so small, that actually such a block might seem a bit overdone.
In this case... Yes. But for your serious production scripts, it's really a "must" for obvious reasons.
- Also, if your script is large, then provide some comment on steps which you think deserves it (like what seems as complex code),
using the "#" character preceding the comment.
- You do not explicitly have to put the statement "exit" or "return" (or something) anywhere, to end the script.
Only, for example, if using an "if" test, some condition turns out to be true, which makes running the script "non desired" or
even "impossible", you might use "exit" to terminate the script right away.
For example, if a script must be run under a certain user account, you might test the useraccount first.
if [ `whoami` != root ]
then
echo "You must run this script as root." exit
fi
Here, the `whoami` will return the account of the user. If it's not "root", the script "exits" immediately.
A further explanation on how to use the "if" statement with "string comparison", will be done in section 2.3.
⇒ Explaining the example script at the beginning of Chapter 2:
You see that I use the "cat" command first, to open and read all lines of the "/apps/myapp/logs/myapp.log" file.
Then, using a pipe "|", all records will be pushed to the "grep" command, which will filter out the lines
containing the string "Error"
Then we use "redirection" so that grep places it's output into the file "/tmp/errlog.txt".
So we know for sure, that /tmp/errlog.txt will only contain error messages and nothing else from the "myapp.log" file.
So, if no errors were found, the "/tmp/errlog.txt" will not have any lines, that is, it contains "0" lines.
Next, something interesting happens. Ofcourse, in shell scripts all sorts of "loop" constructs are possible, as well as
forms of "decision logic". The "If" statement is a form of "decision logic".
Later on we will see the "If" many times.
In this example it works like so:
"If [number of lines in /tmp/errlog.txt > 0]
then
"send a mail to the operator that errors were found"
The "If" logic generally works like this: If .. then .. else ..
However, in this particular example, we do not need the "else" block.
Now, you still might wonder what exactly the [`cat /tmp/errlog.txt | wc -l` -gt 0] does.
The "wc -l" command will count the "number of lines" of anything that it receives from a pipe. Now you see that the "cat" command
is used which opens and reads everything out of "/tmp/errlog.txt", and pushes those records to "wc -l".
Consequently, "wc -l" might have counted zero or more lines, since "/tmp/errlog.txt" might have zero or more lines.
If the number of counts > 0, (or denoted as "-gt 0"), the If condition is "true" and a mail is send.
If the number of counts = 0, then nothing happens.
Now, I only have one small little thing to explain.
Ofcourse, you can always use a command like this cat /tmp/errlog.txt | wc -l in a script.
However, this time we have the command in the "if [ ]" block, so we must tell unix that it can really run it, even if it's within
the [ ] brackets. You can achieve this by placing the command within the `` quotes.
On most keyboards, you find this quote in the upper-left corner, just below the Esc key.
Exercise:
Create, with vi (or other editor), a file in "/tmp" and call it "errlog.txt". Just put a line of arbitrary text in "errlog.txt".
Next, create the file "test.sh" in "/tmp", and put the following code in it:
if [ `cat /tmp/errlog.txt | wc -l` -gt 0 ]
then
echo "the number of lines in errlog.txt is greater than 0"
fi
Once the script file is finished and saved, make it executable:
$ chmod +x test.sh
You can execute "test.sh" using:
$ ./test.sh
Now, experiment with the script when errlog.txt has 0 lines, or > 0 lines.
Question: Can you explain when you get the message "the number of lines in errlog.txt is greater than 0"?
2.2 Variables.
We do not have to create a script to see how variables work in a Unix/Linux shell. Statements from the prompt, will demonstrate them just as well.
⇒ Variable assignments:
Try the following statements:
$ me="Albert"
$ echo $me
Albert
$ var1=5
$ echo $var1
5
$ now=`date`
$ echo $now
Thu Jan 17 20:31:32 2013
So, a variable is set with an assignment of variablename=value. Be sure not to have any white space before or after
the equals sign "=". In the first example, I used double quotes around the string "Albert". Actually, double quotes is only
neccessary when white space is present in the text string.
Once a variable is set, you always refer to it using a "$" character in front of the name, like in "$me".
The first two variables are just "static" values, like a name or a number. The third example is really great!
In this example, the date command is used (which just returns the current "date"), and is placed between `` quotes.
The `` quotes always signals to the shell, that it must "expand" this variable, that is, to run that command.
Or what about this example. Again, we define a variable named "list" in the form of a unix command, which will be executed
at runtime (that is, when you press Enter, or if it's in a script, when the script is run).
$ list=`ls -al | wc -l`
$ echo $list
37
As we know, "ls -al" produces a listing of all files in the current directory. So, when that list is pushed to "wc -l", we just
get the counts returned (that is, the number of files).
A variable will be expanded (to its value) in a string with double quotes (but not in single quotes). Here is what I mean:
$ name="Albert"
$ echo "Hi there $name"
Hi there Albert
⇒ Exporting a variable:
Variables "declared" as above, are local to your current shell instance. They are not garanteed to exist for other scripts and commands.
To create variables that are Global to your session you have to "export" a variable.
Variables that are marked for export are called environment variables, and are available for any command or script
during your session.
In the most "common shells" (like "sh", "bash", and "korn"), use the "export" command like so:
In the second example, the $ORACLE_HOME variable functions like a sort of "alias" to some part of the directory tree.
These sort of variables have great advantages. Suppose that there would exist a "bin" directory like "/apps/oracle/product/10.2/bin,
containing all sorts of programs like for example the program "sqlplus".
Once the ORACLE_HOME variable is defined as above, you can call those utilities using a "shortcut", like for example:
$ $ORACLE_HOME\bin\sqlplus
Note:
Sometimes "a slight detour" is used to export a variable. It amounts to the same thing, but it needs more typing:
Shell scripting, like almost all other scripting environments, uses the "If" or "case" statements, to implement "decision logic".
- use the "if" statement if the logic is based on some condition that's either "true" or "false".
- Use the "case" statement if the logic is based on some value that's one of a number of possible values.
2.3.1 The "if" statement:
In many occasions, your script will perform certain actions if a certain condition is "true".
If that condition is "not true", or "false", optionally an alternative action is done. Here, is the general "If" format is:
If [ "evaluate a certain test between brackets" ] then
statement(s) if the test=true else
other statement(s) if the test=false fi
Always end the "if" statement with "fi", which functions as an "endmarker" to the shell. Note that "fi" is "if" backwards.
The "else" branch is optional. If you do not need it, you can skip it. This is just what was done in the example in section 2.1.
The "[ ]" alsways contains some sort of "test", which evaluates to "true" or "false". Here are a few examples
on what can be "tested":
1: Tests on objects:
[ -f file ]... the "-f" means "test if the file exists"
[ -d dir ].... the "-d" means "test if the directory exists"
[ -s file ]... the "-s" means "test if the file > 0 bytes"
(there are more similar tests...)
2: Tests on nummeric variables:
[ $x -lt $y ]... means "test if $x is lower than or equal $y"
[ $x -le $y ]... means "test if $x is lower than $y"
[ $x -eq $y ]... means "test if $x and $y are equal"
[ $x -gt $y ]... means "test if $x is greater than $y"
[ $x -ge $y ]... means "test if $x is greater than or equal $y"
3: Tests on string variables:
[ "$var" == "string value" ]... means "test if $var contains the same characters as "string value"
[ "$var" != "string value" ]... means "test if $var does NOT have the same characters as "string value"
Note the space after "[" and the space before "]".
----> Intermezzo: The "touch" command:
As an intermezzo, we need to explain the "touch" command first, before we do any exercise. It's not always neccessary to use "vi"
if you "just need a file". If an "empty" file (0 bytes) is good enough, you can simply use the "touch" command, like so:
$ cd /tmp
$ touch errlog.txt
It means that the file "errlog.txt" will be created, although it's completely "empty".
----> End Intermezzo
Exercise:
test on the existence of a file (-f parameter):
- Go to "/tmp" (or your homedir, using "cd ~")
- Use vi to create a shell script called "rmlog.sh"
- Put the following code into "rmlog.sh"
if [ -f /tmp/myapp.log ]
then
rm /tmp/myapp.log
else
echo "no log file found"
fi
It's important to keep a space between the "[", and the string "-f /tmp/myapp.log", and to have a space before the last "]" too.
- After the script has been saved, use "chmod +x rmlog.sh" to make it executable.
- Run the script using "./rmlog.sh"
- Go to "/tmp" and use the command "touch myapp.log"
- Run the script again.
- Go to "/tmp" and check if the logfile still exists or not (using "ls -al myapp.log") .
Note: the "rm" command removes a file.
The exercise above, dealt with the test on the existence of an object, such as a file.
Lets walk trough a test on nummeric variables, this time. If we would make this script:
var1=1
var2=2
if [ $var1 -le $var2 ]
then
echo "Var1 is smallest"
else
echo "Var2 is smallest"
fi
I think you agree that if we would run this script, we would see the message: "Var1 is smallest"
So remember: for "nummerical" comparisons in the "[ ]", use the "lt", "le", "eq", "gt", and "ge" operators.
It's important to realize that, up to now, we have seen "If" tests with respect "on the existence" of an object, and
comparisons between nummeric variables.
How about string tests? That is, suppose a variable contains some string (some characters), and we need to test that.
It's a bit more of the same, but I want to you have a sharp eye on the fact that this time, we use the "==" and "!=" operators.
Here are a few simple examples:
- If you need to determine if variable’s contents is equal to a certain fixed string:
var1=Mary
if [ "$var1" == "Mary" ]
then
echo "It's Mary"
fi
- If you need to determine if variable’s contents is Not equal to a certain fixed string:
var1=Harry
if [ "$var1" != "Mary" ]
then
echo "It's Not Mary"
fi
2.3.2 The "case" statement:
With the "if" statement, you can handle most "decision tree's" in your scripts. However, suppose the number
of options is really fixed. In such cases, using the "case" statement is better.
In the following example we will also use the "read" command. The "read" command makes it possible to get
user input from the keyboard, which usually will be placed into some variable.
You really should try the example below. It's quite cool. Just create a file with vi, name it for example "inputtest.sh",
and put the following code in that file:
Example:
echo "Please type yes or no:"
read answer case $answer in
yes|Yes|y)
echo "You said yes.."
;;
no|n)
echo "You said no.."
;;
q*|Q*)
#Probably the user wants to stop
exit
;;
*)
echo "If none of the above was typed, this is the default.."
;; esac
Note that, just as was the case with the if statement, the "case" statement ends with "esac" which is "case" backwards.
Also note that every "option" must be terminated by ";;".
In the example above, you see indeed a number of options, which represents what the user could key in, like "y" or "n" etc..
The case statement should also have a "default" option, expressed by "*)" which then handles every case which is not covered
by the regular options. However, it's not required.
Example:
Here is another example. This example you probably can't try yourself. But it's a nice illustration on how a Unix system administrator
might program a tape robot, before the backup takes place.
Don't worry about the exact purpose of the script. I only want you to see that I start with a variable DAYNAME,
which, using the date command with a special parameter (not on all unixes it works that way), produces strings like
"Mon", "Tue" etc.. So, if the script runs on monday, DAYNAME=Mon. If the script runs on tuesday, DAYNAME=Tue etc..
Now look at the "case" logic. If for example DAYNAME=Mon, the "tapeutil" command removes certain tapes from certain slots,
and replaces them with new tapes.
The same happens with different slots for the other days.
So, actually, here the "case" statement was a great help for a Unix system administrator.
Again, notice that the "case" statement works great if there are a limited number of options to choose from (like Mon, Tue etc..).
2.4 Loops.
Any scripting environment uses "loop constructs" in order to repeat actions. Ofcourse, unix shell scripts have that too.
Three "main" loop constructs are possible:
for (variable in list)
do Statements
done
while (condition is true)
do Statements
done
until (variable reaches a value, or becomes true)
do Statements
done
For the "while" and "for" loops, a couple of examples is shown below.
⇒ The "For" loop:
This one is very good, if you must work through a "list" of values, or objects (like files).
Once the list is determined, the number of loops is "fixed". For example, you have a list of "100 files" or so, where the statements in the "for" loop must operate on.
Here are a few typical examples:
for i in eat run jump play
do
echo "See Mary $i"
done
Output:
See Mary eat
See Mary run
See Mary jump
See Mary play
Here we have a fixed list of 4 values. The variable $i takes on every value sequentially. Now you may ask: Why not "for $i in.."?
Remember that you declare a variable as for example: "var1=5". So, only after it gets a value, then you refer to it as $var1.
Here is another "for" loop:
for file in `ls`
do
mv $file $file.sql
done
You know that "ls -al" produces a "long listing" of files, meaning that you get a list of filenames, with their sizes, owner etc..
On the other hand, just a simple list of filenames can be obtained using the "ls" command "as is", without the parameters "-al".
As we know, the shell will expand the expression `ls` (note the quotes) at runtime, which produces a list of filenames
inside some directory.
After the list has been produced, the "for" loop opens, and every file is "renamed" to "filename".sql, using the "mv" (move) command.
⇒ The "While" loop:
The "while" loop is used in such a way, that the loop keeps on "looping" while some "condition" remains true.
Here is a very simple example:
i=1
while [ $i -le 10 ]
do
echo "I have printed this $i times.."
i=$(( $i + 1 ))
done
Initially, the "counter" "i" is set to 1. Then the while loop starts. The condition "$i lower than or equal to 10", is true,
since 1 < 10. So, the "echo" statement within the loop is done. Then, the counter "i" is incremented by "1".
So now, "i=2". Next, the condition for the while loop is tested again. Again, it is "true" since 2 < 10.
So now the loop runs for the second time, and the "echo" statement within the loop is executed.
The loop goes on and on, until the counter "i" reaches the value of "10". This time, the condition for the while loop is not "true" anymore,
and so the loop stops.
By the way, the statement to increment a counter as I did in "i=$(( $i + 1 ))" might vary accross shells.
If your shell complains about it, try ((i++)) instead, which is a different way of saying "increment i by one".
Here is another example:
keeplooping=1
echo "type y to loop on, or q to quit"
while [ $keeplooping -eq 1 ] ; do
read quitnever
if [ "$quitnever" = "y" ]
then
echo "type y to loop on, or q to quit"
fi
if [ "$quitnever" = "q" ]
then break;
fi
done
It's a bit of a strange example. If you want to try it, I hope it runs on your system without modifications.
If it does not run right away.. Well, don't worry too much about it. It's only an example.
But, it's interresting to walk through it, because in the loop, we read user input (thanks to the "read" command), and we have two "if" blocks.
First, notice that the variable "keeplooping" is set to "1". The while loop starts and tests if $keeplooping = 1.
This is true, so the loop goes for the first run. Then we read what the user types in: "y" or "q".
What the user types in, will go into the variable "$quitnever". It "$quitnever"=y, then $keeplooping stays "1".
So, we go to the next run of the loop. So, if the user only types in "y", the loop will never stop.
Now, suppose that the user types "q". Then "$quitnever" = "q". This means that we enter the second "if" statement.
Here, we see the "break" command, which always terminates the "while" loop.
We already knew that the "while" loop keeps looping while the "condition" is true. However, as we see here,
there is another way to stop the "while" loop, and that's by using the "break" command in some "if" block.
2.5 Parameters or arguments for scripts.
Often, you will use a parameter (or argument) to supply to a script.
Suppose you have a script that "does something" with a report, but it works with other
(similar) reports as well. Now, you never want to "hardcode" a reportname inside the script.
So, you build your script to be able to use "arguments" (supplied to the script), like in this example:
$ ./processreport.sh ReportFeb2011.txt
So, at another time, you can for example re-use the script as in:
$ ./processreport.sh ReportJan2012.txt
The arguments have certain variable "names" at runtime, which can be very useful:
Here are a few common ones...:
The shell program itself
$0
argument 1 through 9
$1 .. $9
nth argument
${n}
number of supplied parameters
$#
every parameter
$*
errorcode returned by last executed cmd
$?
pid of last background command
$!
Here are a few examples:
Here is a simple Bash script which prints out all its arguments.
#!/bin/bash
#
# Print all arguments (version 1)
#
for arg in $*
do
echo Argument $arg
done
echo Total number of arguments was $#
The `$*' symbol stands for the entire list of arguments and `$#' is the total number of arguments.
So, in the above example you could have started the script like for example
$ ./testscript.sh bike car airplane
The next example is a script that expects a parameter that can be either "start" or "stop",
in order to start/stop a certain application.
So, you would use the control script as in:
$ ./control.ksh start
$ ./control.ksh stop
While the script "control.ksh" might contain something like:
#!/bin/ksh
# purpose: script that will start or stop the app.
case "$1" in
start )
echo "Start the app.. A moment please.."
su - appowner -c '/prj/app/appenviron.sh -e ENV1 -c "app.sh -t start"'
;;
stop )
echo "Stop the app.. A moment please"
su - appowner -c '/prj/app/appenviron.sh -e ENV1 -c "app.sh -t stop"'
;;
* )
echo "Usage: $0 (start | stop)"
exit 1
esac
Well...That's about it! A short note indeed, but hopefully it was usefull...